library(mlr3verse)Intro
mlr3pipelines offers a very flexible way to create data preprocessing steps. This is achieved by a modular approach using PipeOps. For detailed overview check the mlr3book.
Recommended prior readings:
This post covers:
- How to apply different preprocessing steps on different features
- How to branch different preprocessing steps, which allows to select the best performing path
- How to tune the whole pipeline
Prerequisites
We load the mlr3verse package which pulls in the most important packages for this example.
We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented.
set.seed(7832)
lgr::get_logger("mlr3")$set_threshold("warn")
lgr::get_logger("bbotk")$set_threshold("warn")The Pima Indian Diabetes classification task will be used.
task_pima = tsk("pima")
skimr::skim(task_pima$data())| Name | task_pima$data() |
| Number of rows | 768 |
| Number of columns | 9 |
| Key | NULL |
| _______________________ | |
| Column type frequency: | |
| factor | 1 |
| numeric | 8 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| diabetes | 0 | 1 | FALSE | 2 | neg: 500, pos: 268 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| age | 0 | 1.00 | 33.24 | 11.76 | 21.00 | 24.00 | 29.00 | 41.00 | 81.00 | ▇▃▁▁▁ |
| glucose | 5 | 0.99 | 121.69 | 30.54 | 44.00 | 99.00 | 117.00 | 141.00 | 199.00 | ▁▇▇▃▂ |
| insulin | 374 | 0.51 | 155.55 | 118.78 | 14.00 | 76.25 | 125.00 | 190.00 | 846.00 | ▇▂▁▁▁ |
| mass | 11 | 0.99 | 32.46 | 6.92 | 18.20 | 27.50 | 32.30 | 36.60 | 67.10 | ▅▇▃▁▁ |
| pedigree | 0 | 1.00 | 0.47 | 0.33 | 0.08 | 0.24 | 0.37 | 0.63 | 2.42 | ▇▃▁▁▁ |
| pregnant | 0 | 1.00 | 3.85 | 3.37 | 0.00 | 1.00 | 3.00 | 6.00 | 17.00 | ▇▃▂▁▁ |
| pressure | 35 | 0.95 | 72.41 | 12.38 | 24.00 | 64.00 | 72.00 | 80.00 | 122.00 | ▁▃▇▂▁ |
| triceps | 227 | 0.70 | 29.15 | 10.48 | 7.00 | 22.00 | 29.00 | 36.00 | 99.00 | ▆▇▁▁▁ |
Selection of features for preprocessing steps
Several features of the pima task have missing values:
task_pima$missings()diabetes age glucose insulin mass pedigree pregnant pressure triceps
0 0 5 374 11 0 0 35 227 A common approach in such situations is to impute the missing values and to add a missing indicator column as explained in the Impute missing variables post. Suppose we want to use
PipeOpImputeHiston features “glucose”, “mass” and “pressure” which have only few missing values andPipeOpImputeMedianon features “insulin” and “triceps” which have much more missing values.
In the following subsections, we show two approaches to implement this.
1. Consider all features and apply the preprocessing step only to certain features
Using the affect_columns argument of a PipeOp to define the variables on which a PipeOp will operate with an appropriate Selector function:
# imputes values based on histogram
imputer_hist = po("imputehist",
affect_columns = selector_name(c("glucose", "mass", "pressure")))
# imputes values using the median
imputer_median = po("imputemedian",
affect_columns = selector_name(c("insulin", "triceps")))
# adds an indicator column for each feature with missing values
miss_ind = po("missind")When PipeOps are constructed this way, they will perform the specified preprocessing step on the appropriate features and pass all the input features to the subsequent steps:
# no missings in "glucose", "mass" and "pressure"
imputer_hist$train(list(task_pima))[[1]]$missings()diabetes age insulin pedigree pregnant triceps glucose mass pressure
0 0 374 0 0 227 0 0 0 # no missings in "insulin" and "triceps"
imputer_median$train(list(task_pima))[[1]]$missings()diabetes age glucose mass pedigree pregnant pressure insulin triceps
0 0 5 11 0 0 35 0 0 We construct a pipeline that combines imputer_hist and imputer_median. Here, imputer_hist will impute the features “glucose”, “mass” and “pressure”, and imputer_median will impute “insulin” and “triceps”. In each preprocessing step, all the input features are passed to the next step. In the end, we obtain a data set without missing values:
# combine the two impuation methods
impute_graph = imputer_hist %>>% imputer_median
impute_graph$plot(html = FALSE)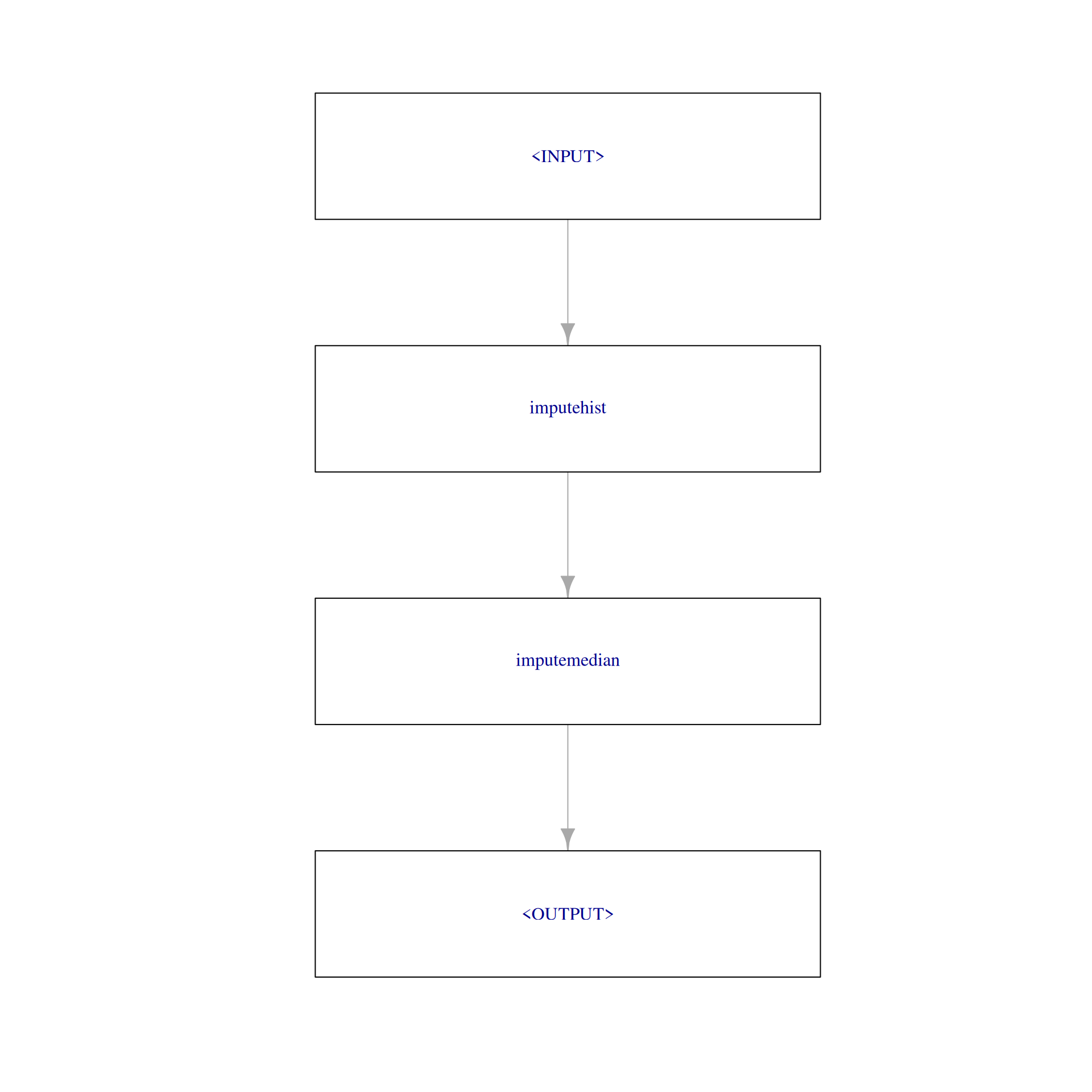
impute_graph$train(task_pima)[[1]]$missings()diabetes age pedigree pregnant glucose mass pressure insulin triceps
0 0 0 0 0 0 0 0 0 The PipeOpMissInd operator replaces features with missing values with a missing value indicator:
miss_ind$train(list(task_pima))[[1]]$data() diabetes missing_glucose missing_insulin missing_mass missing_pressure missing_triceps
<fctr> <fctr> <fctr> <fctr> <fctr> <fctr>
1: pos present missing present present present
2: neg present missing present present present
3: pos present missing present present missing
4: neg present present present present present
5: pos present present present present present
---
764: neg present present present present present
765: neg present missing present present present
766: neg present present present present present
767: pos present missing present present missing
768: neg present missing present present presentObviously, this step can not be applied to the already imputed data as there are no missing values. If we want to combine the previous two imputation steps with a third step that adds missing value indicators, we would need to PipeOpCopy the data two times and supply the first copy to impute_graph and the second copy to miss_ind using gunion(). Finally, the two outputs can be combined with PipeOpFeatureUnion:
impute_missind = po("copy", 2) %>>%
gunion(list(impute_graph, miss_ind)) %>>%
po("featureunion")
impute_missind$plot(html = FALSE)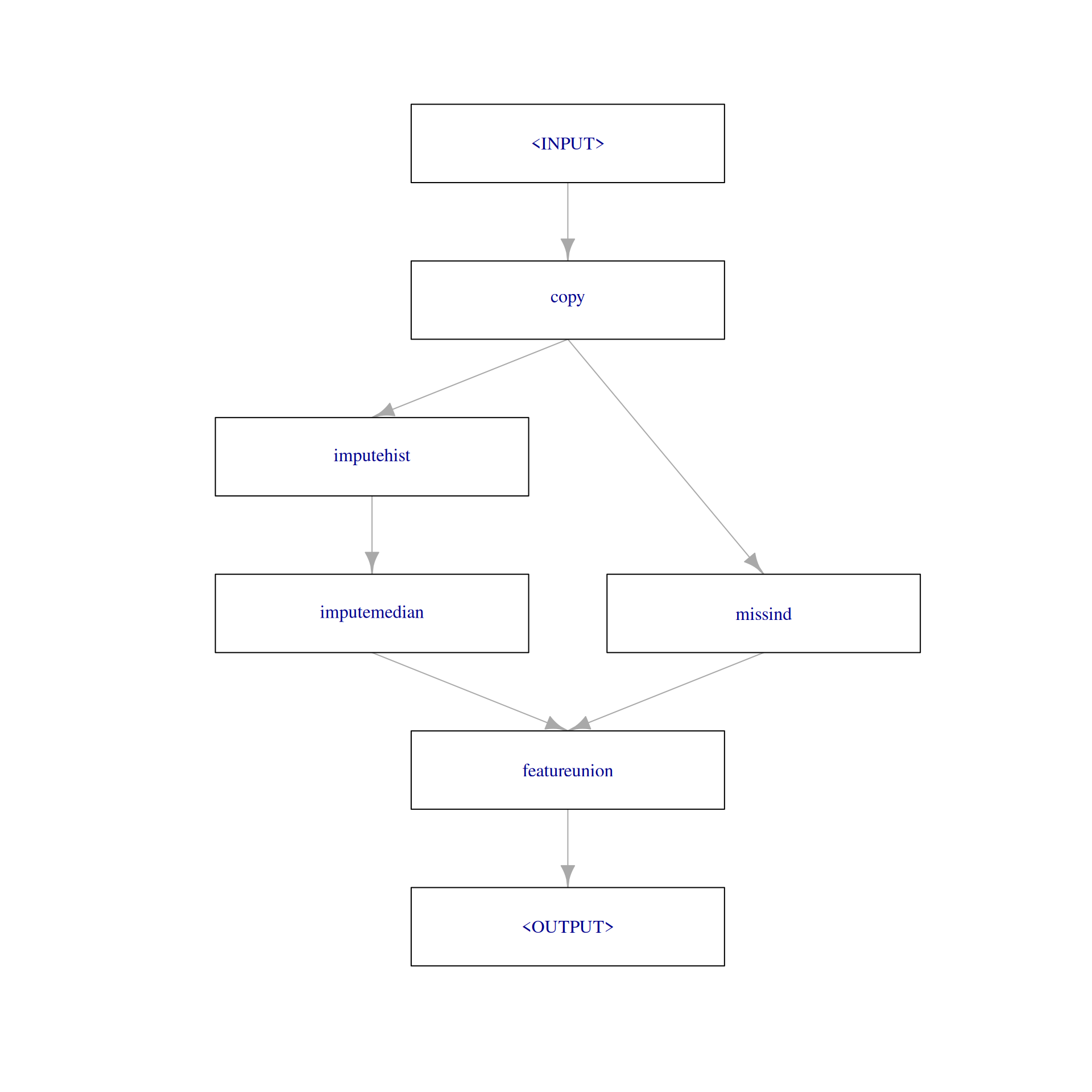
impute_missind$train(task_pima)[[1]]$data() diabetes age pedigree pregnant glucose mass pressure insulin triceps missing_glucose missing_insulin
<fctr> <num> <num> <num> <num> <num> <num> <num> <num> <fctr> <fctr>
1: pos 50 0.627 6 148 33.6 72 125 35 present missing
2: neg 31 0.351 1 85 26.6 66 125 29 present missing
3: pos 32 0.672 8 183 23.3 64 125 29 present missing
4: neg 21 0.167 1 89 28.1 66 94 23 present present
5: pos 33 2.288 0 137 43.1 40 168 35 present present
---
764: neg 63 0.171 10 101 32.9 76 180 48 present present
765: neg 27 0.340 2 122 36.8 70 125 27 present missing
766: neg 30 0.245 5 121 26.2 72 112 23 present present
767: pos 47 0.349 1 126 30.1 60 125 29 present missing
768: neg 23 0.315 1 93 30.4 70 125 31 present missing
missing_mass missing_pressure missing_triceps
<fctr> <fctr> <fctr>
1: present present present
2: present present present
3: present present missing
4: present present present
5: present present present
---
764: present present present
765: present present present
766: present present present
767: present present missing
768: present present present2. Select the features for each preprocessing step and apply the preprocessing steps to this subset
We can use the PipeOpSelect to select the appropriate features and then apply the desired impute PipeOp on them:
imputer_hist_2 = po("select",
selector = selector_name(c("glucose", "mass", "pressure")),
id = "slct1") %>>% # unique id so we can combine it in a pipeline with other select PipeOps
po("imputehist")
imputer_hist_2$plot(html = FALSE)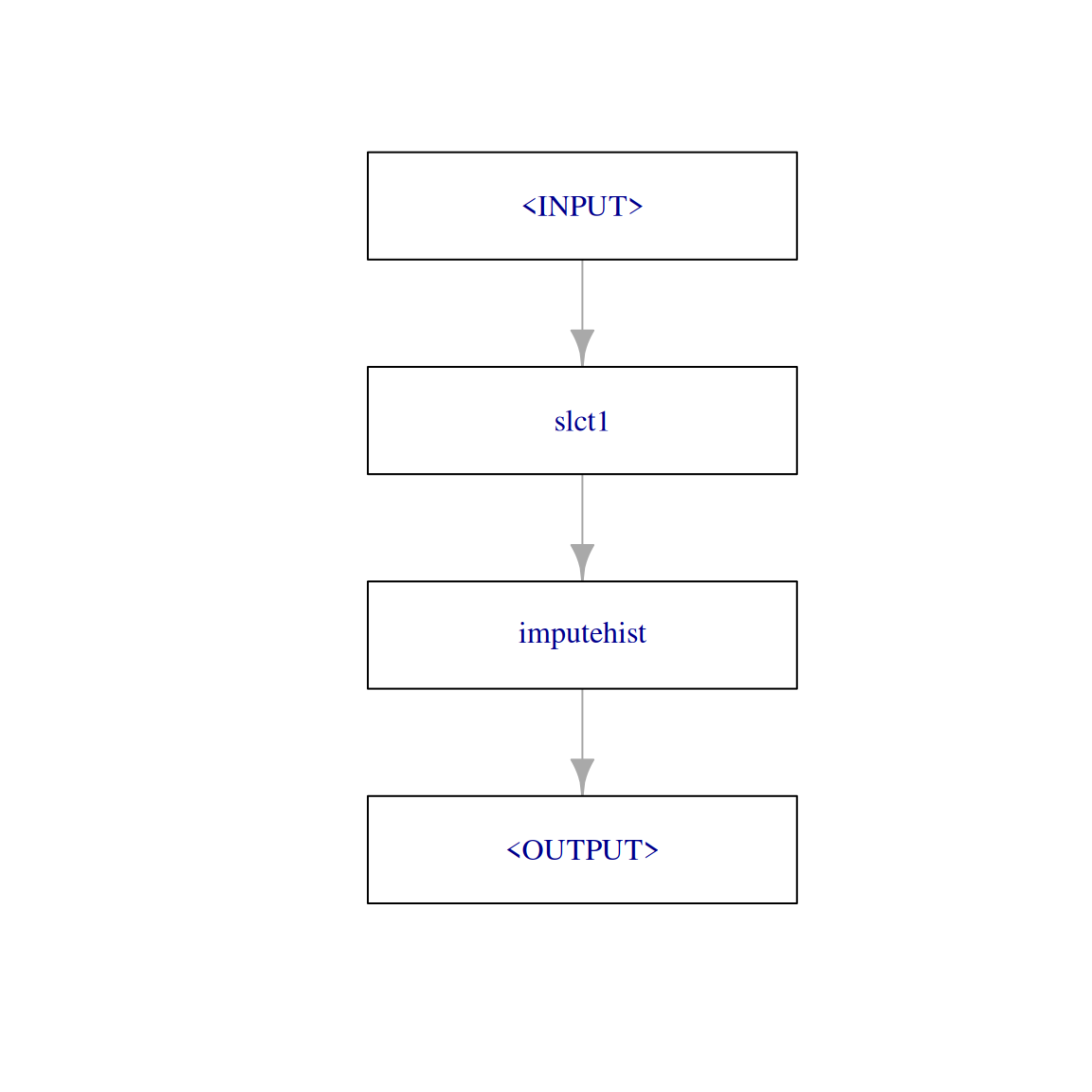
imputer_hist_2$train(task_pima)[[1]]$data() diabetes glucose mass pressure
<fctr> <num> <num> <num>
1: pos 148 33.6 72
2: neg 85 26.6 66
3: pos 183 23.3 64
4: neg 89 28.1 66
5: pos 137 43.1 40
---
764: neg 101 32.9 76
765: neg 122 36.8 70
766: neg 121 26.2 72
767: pos 126 30.1 60
768: neg 93 30.4 70imputer_median_2 =
po("select", selector = selector_name(c("insulin", "triceps")), id = "slct2") %>>%
po("imputemedian")
imputer_median_2$train(task_pima)[[1]]$data() diabetes insulin triceps
<fctr> <num> <num>
1: pos 125 35
2: neg 125 29
3: pos 125 29
4: neg 94 23
5: pos 168 35
---
764: neg 180 48
765: neg 125 27
766: neg 112 23
767: pos 125 29
768: neg 125 31To reproduce the result of the fist example (1.), we need to copy the data four times and apply imputer_hist_2, imputer_median_2 and miss_ind on each of the three copies. The fourth copy is required to select the features without missing values and to append it to the final result. We can do this as follows:
other_features = task_pima$feature_names[task_pima$missings()[-1] == 0]
imputer_missind_2 = po("copy", 4) %>>%
gunion(list(imputer_hist_2,
imputer_median_2,
miss_ind,
po("select", selector = selector_name(other_features), id = "slct3"))) %>>%
po("featureunion")
imputer_missind_2$plot(html = FALSE)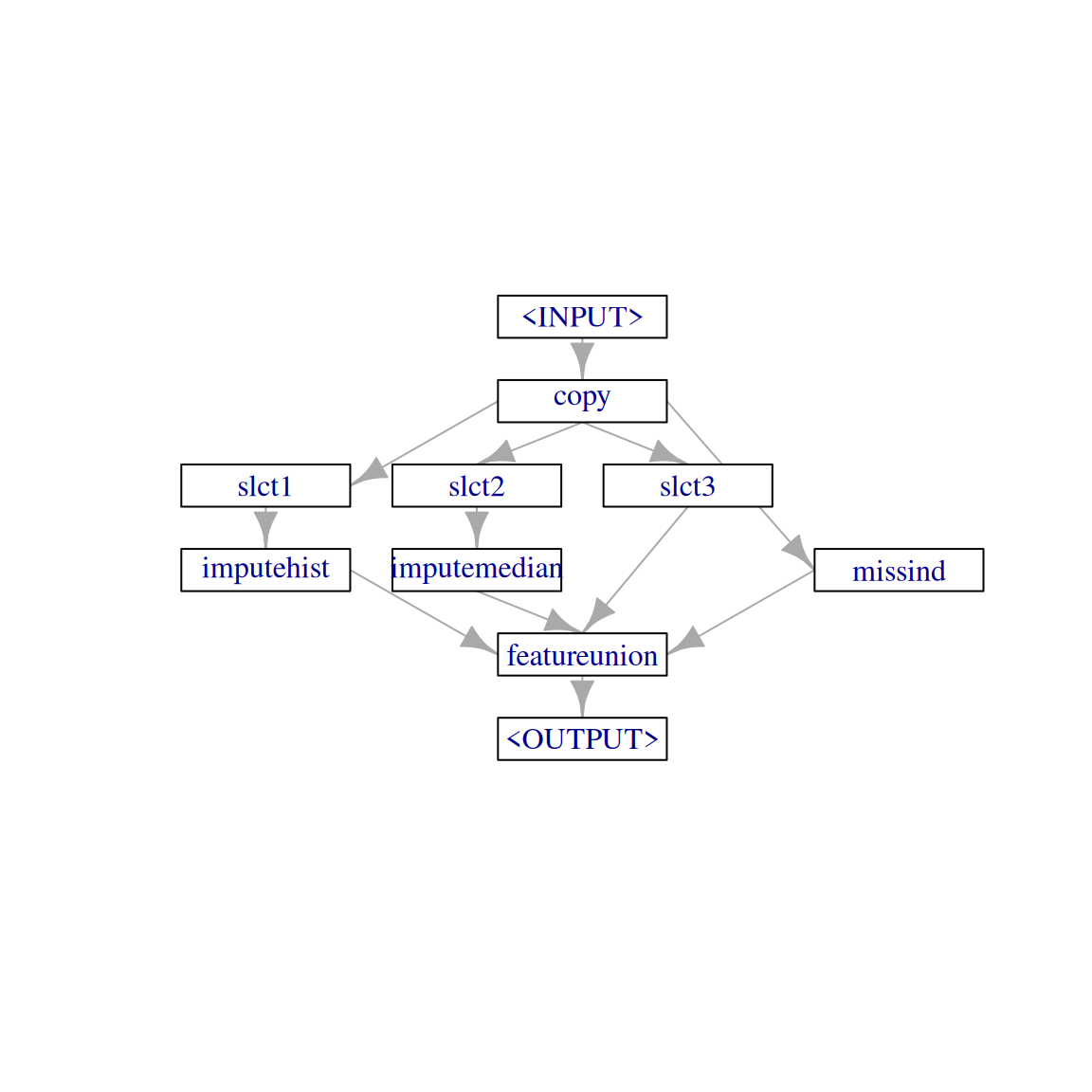
imputer_missind_2$train(task_pima)[[1]]$data() diabetes glucose mass pressure insulin triceps missing_glucose missing_insulin missing_mass missing_pressure
<fctr> <num> <num> <num> <num> <num> <fctr> <fctr> <fctr> <fctr>
1: pos 148 33.6 72 125 35 present missing present present
2: neg 85 26.6 66 125 29 present missing present present
3: pos 183 23.3 64 125 29 present missing present present
4: neg 89 28.1 66 94 23 present present present present
5: pos 137 43.1 40 168 35 present present present present
---
764: neg 101 32.9 76 180 48 present present present present
765: neg 122 36.8 70 125 27 present missing present present
766: neg 121 26.2 72 112 23 present present present present
767: pos 126 30.1 60 125 29 present missing present present
768: neg 93 30.4 70 125 31 present missing present present
missing_triceps age pedigree pregnant
<fctr> <num> <num> <num>
1: present 50 0.627 6
2: present 31 0.351 1
3: missing 32 0.672 8
4: present 21 0.167 1
5: present 33 2.288 0
---
764: present 63 0.171 10
765: present 27 0.340 2
766: present 30 0.245 5
767: missing 47 0.349 1
768: present 23 0.315 1Note that when there is one input channel, it is automatically copied as many times as needed for the downstream PipeOps. In other words, the code above works also without po("copy", 4):
imputer_missind_3 = gunion(list(imputer_hist_2,
imputer_median_2,
miss_ind,
po("select", selector = selector_name(other_features), id = "slct3"))) %>>%
po("featureunion")
imputer_missind_3$train(task_pima)[[1]]$data() diabetes glucose mass pressure insulin triceps missing_glucose missing_insulin missing_mass missing_pressure
<fctr> <num> <num> <num> <num> <num> <fctr> <fctr> <fctr> <fctr>
1: pos 148 33.6 72 125 35 present missing present present
2: neg 85 26.6 66 125 29 present missing present present
3: pos 183 23.3 64 125 29 present missing present present
4: neg 89 28.1 66 94 23 present present present present
5: pos 137 43.1 40 168 35 present present present present
---
764: neg 101 32.9 76 180 48 present present present present
765: neg 122 36.8 70 125 27 present missing present present
766: neg 121 26.2 72 112 23 present present present present
767: pos 126 30.1 60 125 29 present missing present present
768: neg 93 30.4 70 125 31 present missing present present
missing_triceps age pedigree pregnant
<fctr> <num> <num> <num>
1: present 50 0.627 6
2: present 31 0.351 1
3: missing 32 0.672 8
4: present 21 0.167 1
5: present 33 2.288 0
---
764: present 63 0.171 10
765: present 27 0.340 2
766: present 30 0.245 5
767: missing 47 0.349 1
768: present 23 0.315 1Usually, po("copy") is required when there are more than one input channels and multiple output channels, and their numbers do not match.
Branching
We can not know if the combination of a learner with this preprocessing graph will benefit from the imputation steps and the added missing value indicators. Maybe it would have been better to just use imputemedian on all the variables. We could investigate this assumption by adding an alternative path to the graph with the mentioned imputemedian. This is possible using the “branch” PipeOp:
imputer_median_3 = po("imputemedian", id = "simple_median") # add the id so it does not clash with `imputer_median`
branches = c("impute_missind", "simple_median") # names of the branches
graph_branch = po("branch", branches) %>>%
gunion(list(impute_missind, imputer_median_3)) %>>%
po("unbranch")
graph_branch$plot(html = FALSE)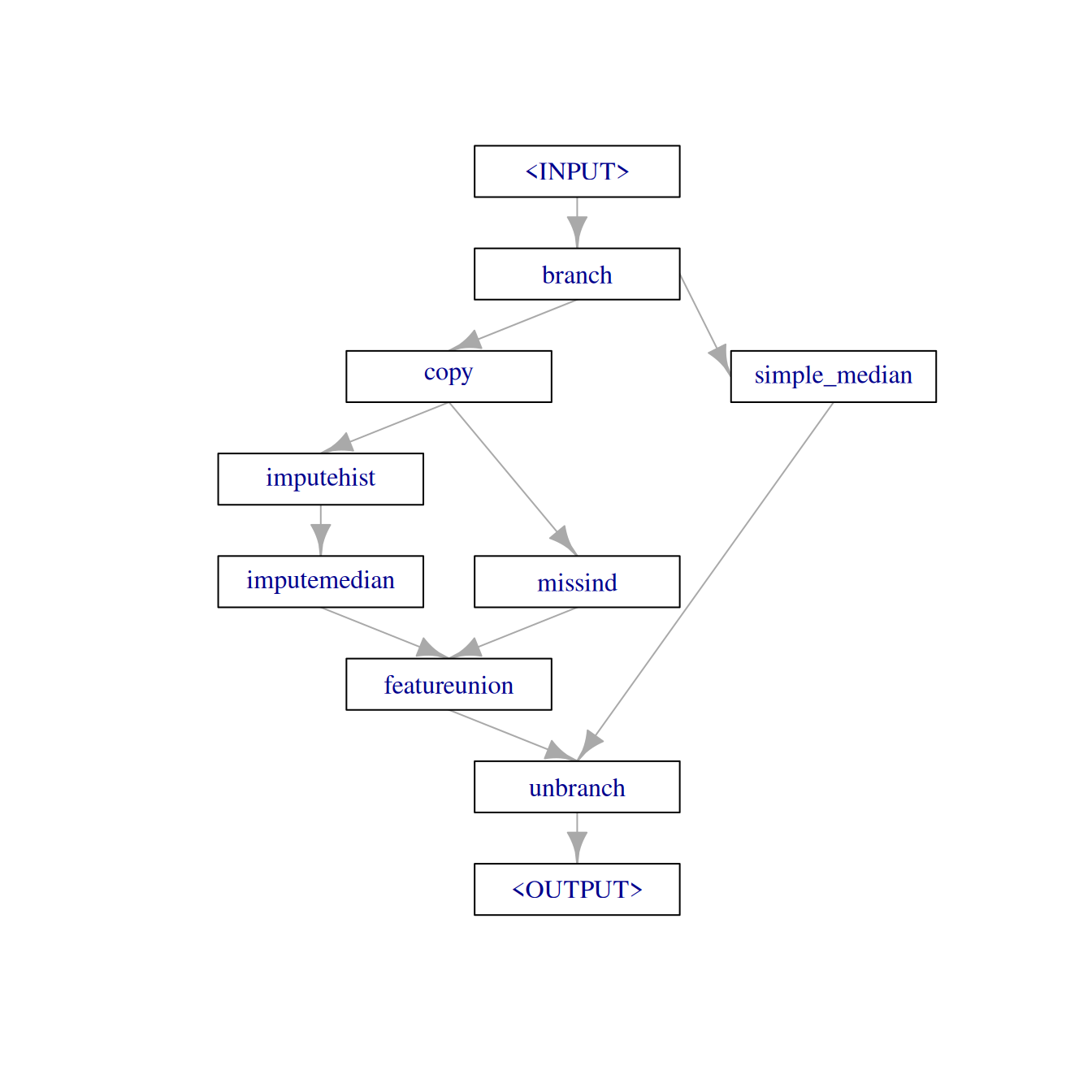
Tuning the pipeline
To finalize the graph, we combine it with a rpart learner:
graph = graph_branch %>>%
lrn("classif.rpart")
graph$plot(html = FALSE)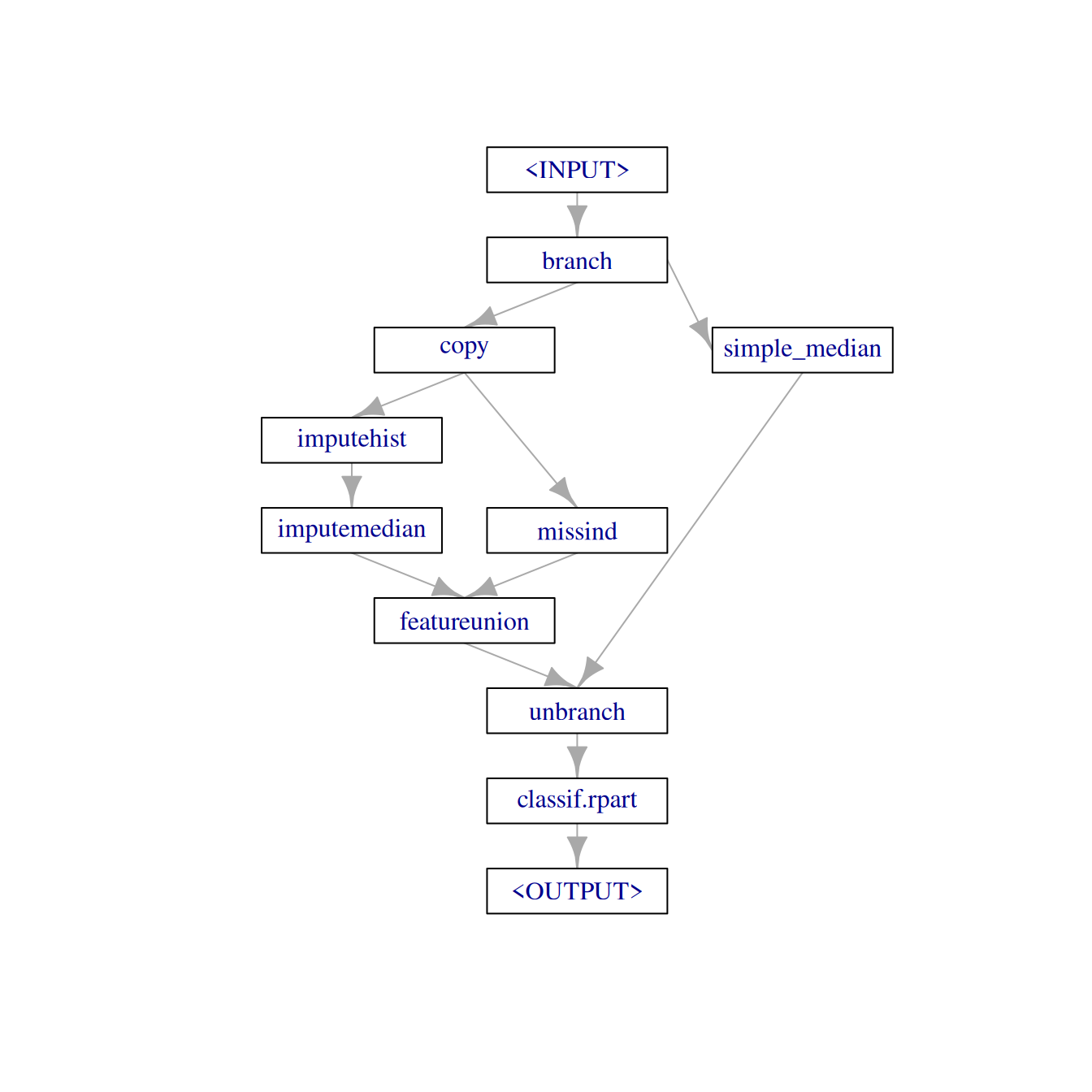
To define the parameters to be tuned, we first check the available ones in the graph:
as.data.table(graph$param_set)[, .(id, class, lower, upper, nlevels)] id class lower upper nlevels
<char> <char> <num> <num> <num>
1: branch.selection ParamFct NA NA 2
2: imputehist.affect_columns ParamUty NA NA Inf
3: imputemedian.affect_columns ParamUty NA NA Inf
4: missind.which ParamFct NA NA 2
5: missind.type ParamFct NA NA 4
6: missind.affect_columns ParamUty NA NA Inf
7: simple_median.affect_columns ParamUty NA NA Inf
8: classif.rpart.cp ParamDbl 0 1 Inf
9: classif.rpart.keep_model ParamLgl NA NA 2
10: classif.rpart.maxcompete ParamInt 0 Inf Inf
11: classif.rpart.maxdepth ParamInt 1 30 30
12: classif.rpart.maxsurrogate ParamInt 0 Inf Inf
13: classif.rpart.minbucket ParamInt 1 Inf Inf
14: classif.rpart.minsplit ParamInt 1 Inf Inf
15: classif.rpart.surrogatestyle ParamInt 0 1 2
16: classif.rpart.usesurrogate ParamInt 0 2 3
17: classif.rpart.xval ParamInt 0 Inf InfWe decide to jointly tune the "branch.selection", "classif.rpart.cp" and "classif.rpart.minbucket" hyperparameters:
search_space = ps(
branch.selection = p_fct(c("impute_missind", "simple_median")),
classif.rpart.cp = p_dbl(0.001, 0.1),
classif.rpart.minbucket = p_int(1, 10))In order to tune the graph, it needs to be converted to a learner:
graph_learner = as_learner(graph)
cv3 = rsmp("cv", folds = 3)
cv3$instantiate(task_pima) # to generate folds for cross validation
instance = tune(
tuner = tnr("random_search"),
task = task_pima,
learner = graph_learner,
resampling = rsmp("cv", folds = 3),
measure = msr("classif.ce"),
search_space = search_space,
term_evals = 5)
as.data.table(instance$archive, unnest = NULL, exclude_columns = c("x_domain", "uhash", "resample_result")) branch.selection classif.rpart.cp classif.rpart.minbucket classif.ce runtime_learners timestamp warnings
<char> <num> <int> <num> <num> <POSc> <int>
1: simple_median 0.02172886 2 0.2799479 0.622 2026-02-27 15:51:29 0
2: impute_missind 0.07525939 1 0.2760417 0.804 2026-02-27 15:51:29 0
3: impute_missind 0.09207969 3 0.2773438 0.788 2026-02-27 15:51:29 0
4: impute_missind 0.03984117 6 0.2721354 0.826 2026-02-27 15:51:30 0
5: impute_missind 0.09872643 7 0.2773438 0.828 2026-02-27 15:51:30 0
errors batch_nr
<int> <int>
1: 0 1
2: 0 2
3: 0 3
4: 0 4
5: 0 5The best performance in this short tuned experiment was achieved with:
instance$result branch.selection classif.rpart.cp classif.rpart.minbucket learner_param_vals x_domain classif.ce
<char> <num> <int> <list> <list> <num>
1: impute_missind 0.03984117 6 <list[9]> <list[3]> 0.2721354Conclusion
This post shows ways on how to specify features on which preprocessing steps are to be performed. In addition it shows how to create alternative paths in the learner graph. The preprocessing steps that can be used are not limited to imputation. Check the list of available PipeOp.