The website features runtime benchmarks of the paradox package now.
Feature Selection Filter
Feature Filters quantify the importance of each feature of a Task by assigning them a numerical score. In a second step, features can be selected by either selecting a fixed absolute or relative frequency of the best features, or by thresholding on the score value.
The Filter PipeOp allows to use filters as a preprocessing step.
Example Usage
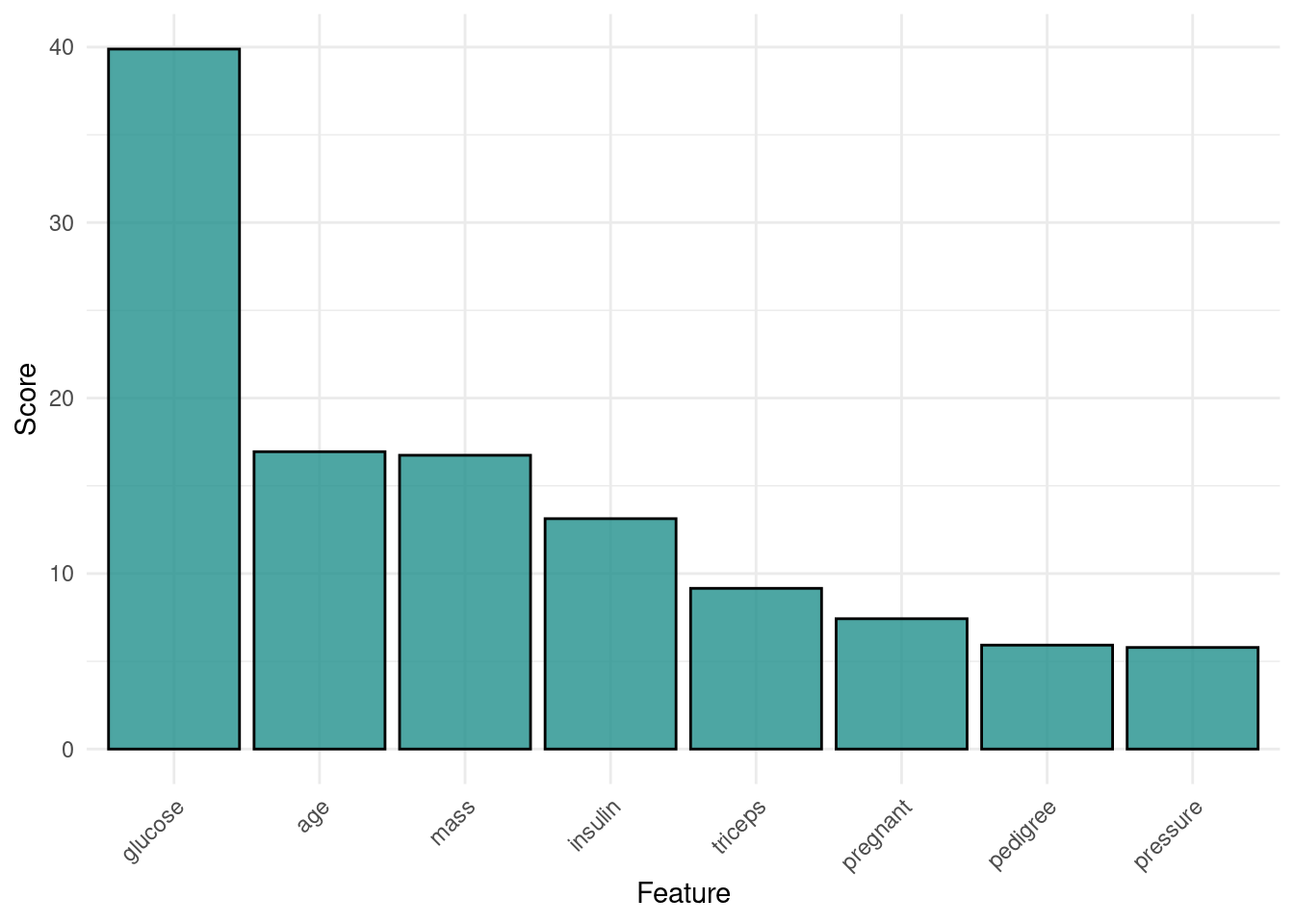
Use the \(-\log_{10}()\)-transformed \(p\)-values of a Kruskal-Wallis rank sum test (implemented in kruskal.test()) for filtering features of the Pima Indian Diabetes tasks.
library("mlr3verse")
Loading required package: mlr3
# retrieve a tasktask =tsk("pima")# retrieve a filterfilter =flt("kruskal_test")# calculate scoresfilter$calculate(task)# access scoresfilter$scores
glucose age mass insulin triceps pregnant pedigree pressure
39.885381 16.942901 16.740864 13.127828 9.158113 7.426955 5.922431 5.788607
# plot scoresautoplot(filter)
# subset task to 3 most important featurestask$select(head(names(filter$scores), 3))task$feature_names