requireNamespace("DiceKriging")Loading required namespace: DiceKrigingrequireNamespace("DiceKriging")Loading required namespace: DiceKrigingThis is the first part of the practical tuning series. The other parts can be found here:
In this post, we demonstrate how to optimize the hyperparameters of a support vector machine (SVM). We are using the mlr3 machine learning framework with the mlr3tuning extension package.
First, we start by showing the basic building blocks of mlr3tuning and tune the cost and gamma hyperparameters of an SVM with a radial basis function on the Iris data set. After that, we use transformations to tune the both hyperparameters on the logarithmic scale. Next, we explain the importance of dependencies to tune hyperparameters like degree which are dependent on the choice of kernel. After that, we fit an SVM with optimized hyperparameters on the full dataset. Finally, nested resampling is used to compute an unbiased performance estimate of our tuned SVM.
We load the mlr3verse package which pulls in the most important packages for this example.
library(mlr3verse)We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
lgr::get_logger("mlr3")$set_threshold("warn")
lgr::get_logger("bbotk")$set_threshold("warn")In the example, we use the Iris data set which classifies 150 flowers in three species of Iris. The flowers are characterized by sepal length and width and petal length and width. The Iris data set allows us to quickly fit models to it. However, the influence of hyperparameter tuning on the predictive performance might be minor. Other data sets might give more meaningful tuning results.
# retrieve the task from mlr3
task = tsk("iris")
# generate a quick textual overview using the skimr package
skimr::skim(task$data())| Name | task$data() |
| Number of rows | 150 |
| Number of columns | 5 |
| Key | NULL |
| _______________________ | |
| Column type frequency: | |
| factor | 1 |
| numeric | 4 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| Species | 0 | 1 | FALSE | 3 | set: 50, ver: 50, vir: 50 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| Petal.Length | 0 | 1 | 3.76 | 1.77 | 1.0 | 1.6 | 4.35 | 5.1 | 6.9 | ▇▁▆▇▂ |
| Petal.Width | 0 | 1 | 1.20 | 0.76 | 0.1 | 0.3 | 1.30 | 1.8 | 2.5 | ▇▁▇▅▃ |
| Sepal.Length | 0 | 1 | 5.84 | 0.83 | 4.3 | 5.1 | 5.80 | 6.4 | 7.9 | ▆▇▇▅▂ |
| Sepal.Width | 0 | 1 | 3.06 | 0.44 | 2.0 | 2.8 | 3.00 | 3.3 | 4.4 | ▁▆▇▂▁ |
We choose the support vector machine implementation from the e1071 package (which is based on LIBSVM) and use it as a classification machine by setting type to "C-classification".
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")For tuning, it is important to create a search space that defines the type and range of the hyperparameters. A learner stores all information about its hyperparameters in the slot $param_set. Not all parameters are tunable. We have to choose a subset of the hyperparameters we want to tune.
as.data.table(learner$param_set)[, .(id, class, lower, upper, nlevels)]We use the to_tune() function to define the range over which the hyperparameter should be tuned. We opt for the cost and gamma hyperparameters of the radial kernel and set the tuning ranges with lower and upper bounds.
learner$param_set$values$cost = to_tune(0.1, 10)
learner$param_set$values$gamma = to_tune(0, 5)We specify how to evaluate the performance of the different hyperparameter configurations. For this, we choose 3-fold cross validation as the resampling strategy and the classification error as the performance measure.
resampling = rsmp("cv", folds = 3)
measure = msr("classif.ce")Usually, we have to select a budget for the tuning. This is done by choosing a Terminator, which stops the tuning e.g. after a performance level is reached or after a given time. However, some tuners like grid search terminate themselves. In this case, we choose a terminator that never stops and the tuning is not stopped before all grid points are evaluated.
terminator = trm("none")At this point, we can construct a TuningInstanceBatchSingleCrit that describes the tuning problem.
instance = ti(
task = task,
learner = learner,
resampling = resampling,
measure = measure,
terminator = terminator
)
print(instance)
── <TuningInstanceBatchSingleCrit> ─────────────────────────────────────────────────────────────────────────────────────
• State: Not optimized
• Objective: <ObjectiveTuningBatch>
• Search Space:
id class lower upper nlevels
<char> <char> <num> <num> <num>
1: cost ParamDbl 0.1 10 Inf
2: gamma ParamDbl 0.0 5 Inf
• Terminator: <TerminatorNone>Finally, we have to choose a Tuner. Grid Search discretizes numeric parameters into a given resolution and constructs a grid from the Cartesian product of these sets. Categorical parameters produce a grid over all levels specified in the search space. In this example, we only use a resolution of 5 to keep the runtime low. Usually, a higher resolution is used to create a denser grid.
tuner = tnr("grid_search", resolution = 5)
print(tuner)
── <TunerBatchGridSearch>: Grid Search ─────────────────────────────────────────────────────────────────────────────────
• Parameters: batch_size=1, resolution=5
• Parameter classes: <ParamLgl>, <ParamInt>, <ParamDbl>, and <ParamFct>
• Properties: dependencies, single-crit, and multi-crit
• Packages: mlr3tuning and bbotkWe can preview the proposed configurations by using generate_design_grid(). This function is internally executed by TunerBatchGridSearch.
generate_design_grid(learner$param_set$search_space(), resolution = 5)<Design> with 25 rows:
cost gamma
<num> <num>
1: 0.100 0.00
2: 0.100 1.25
3: 0.100 2.50
4: 0.100 3.75
5: 0.100 5.00
6: 2.575 0.00
7: 2.575 1.25
8: 2.575 2.50
9: 2.575 3.75
10: 2.575 5.00
11: 5.050 0.00
12: 5.050 1.25
13: 5.050 2.50
14: 5.050 3.75
15: 5.050 5.00
16: 7.525 0.00
17: 7.525 1.25
18: 7.525 2.50
19: 7.525 3.75
20: 7.525 5.00
21: 10.000 0.00
22: 10.000 1.25
23: 10.000 2.50
24: 10.000 3.75
25: 10.000 5.00
cost gamma
<num> <num>We trigger the tuning by passing the TuningInstanceBatchSingleCrit to the $optimize() method of the Tuner. The instance is modified in-place.
tuner$optimize(instance) cost gamma learner_param_vals x_domain classif.ce
<num> <num> <list> <list> <num>
1: 2.575 2.5 <list[4]> <list[2]> 0.04666667We plot the performances depending on the evaluated cost and gamma values.
autoplot(instance, type = "surface", cols_x = c("cost", "gamma"),
learner = lrn("regr.km"))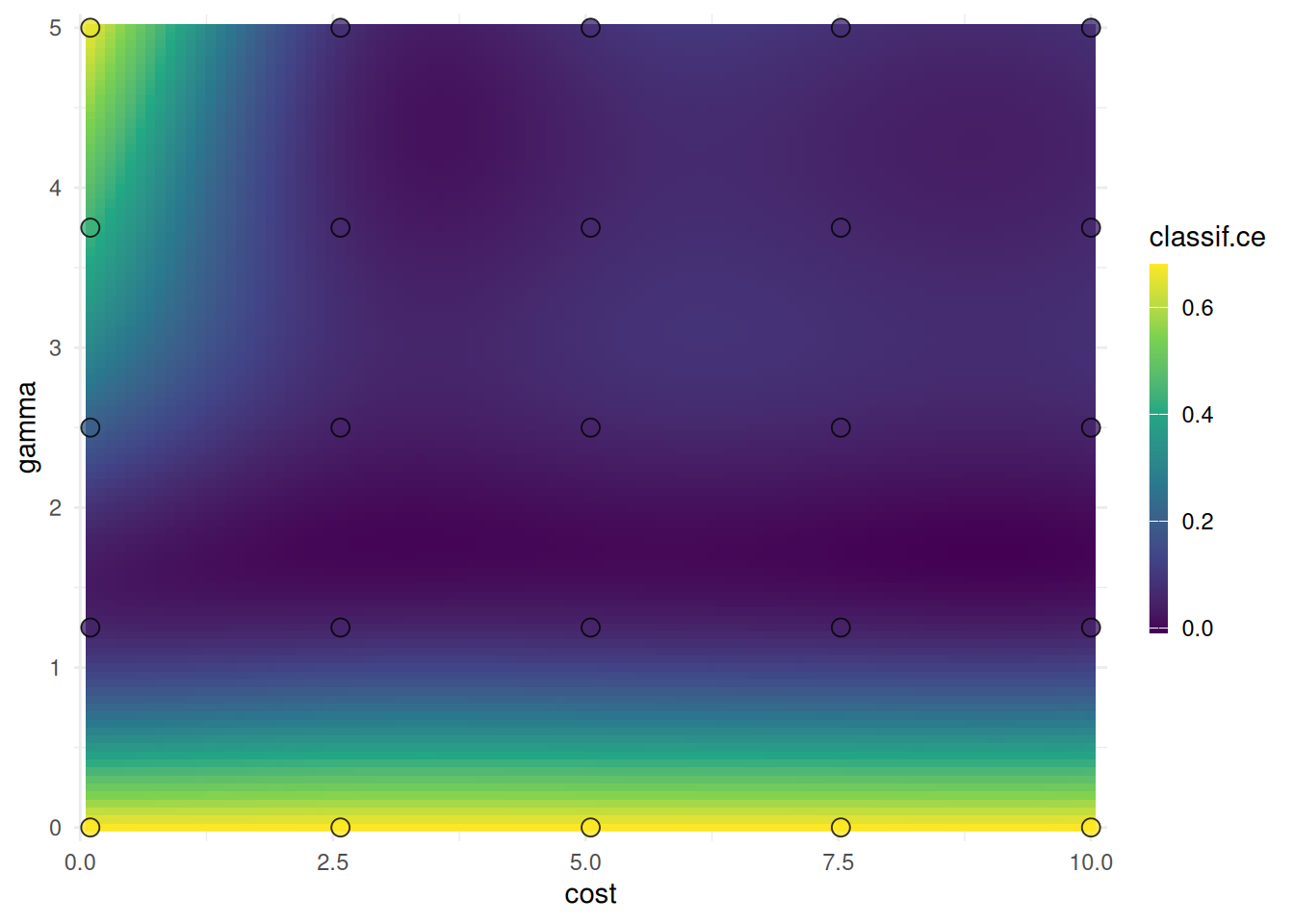
The points mark the evaluated cost and gamma values. We should not infer the performance of new values from the heatmap since it is only an interpolation. However, we can see the general interaction between the hyperparameters.
Tuning a learner can be shortened by using the tune()-shortcut.
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")
learner$param_set$values$cost = to_tune(0.1, 10)
learner$param_set$values$gamma = to_tune(0, 5)
instance = tune(
tuner = tnr("grid_search", resolution = 5),
task = tsk("iris"),
learner = learner,
resampling = rsmp ("holdout"),
measure = msr("classif.ce")
)Next, we want to tune the cost and gamma hyperparameter more efficiently. It is recommended to tune cost and gamma on the logarithmic scale (Hsu et al. 2003). The log transformation emphasizes smaller cost and gamma values but also creates large values. Therefore, we use a log transformation to emphasize this region of the search space with a denser grid.
Generally speaking, transformations can be used to convert hyperparameters to a new scale. These transformations are applied before the proposed configuration is passed to the Learner. We can directly define the transformation in the to_tune() function. The lower and upper bound is set on the original scale.
learner = lrn("classif.svm", type = "C-classification", kernel = "radial")
# tune from 2^-15 to 2^15 on a log scale
learner$param_set$values$cost = to_tune(p_dbl(-15, 15, trafo = function(x) 2^x))
# tune from 2^-15 to 2^5 on a log scale
learner$param_set$values$gamma = to_tune(p_dbl(-15, 5, trafo = function(x) 2^x))Transformations to the log scale are the ones most commonly used. We can use a shortcut for this transformation. The lower and upper bound is set on the transformed scale.
learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))We use the tune()-shortcut to run the tuning.
instance = tune(
tuner = tnr("grid_search", resolution = 5),
task = task,
learner = learner,
resampling = resampling,
measure = measure
)The hyperparameter values after the transformation are stored in the x_domain column as lists. We can expand these lists into multiple columns by using as.data.table(). The hyperparameter names are prefixed by x_domain.
as.data.table(instance$archive)[, .(cost, gamma, classif.ce)] cost gamma classif.ce
<num> <num> <num>
1: 11.512925 5.756463 0.66000000
2: 0.000000 -11.512925 0.58666667
3: -5.756463 -5.756463 0.58666667
4: 11.512925 -5.756463 0.05333333
5: 0.000000 -5.756463 0.24000000
6: -5.756463 0.000000 0.58666667
7: -11.512925 0.000000 0.58666667
8: 5.756463 0.000000 0.06000000
9: 0.000000 0.000000 0.05333333
10: 11.512925 11.512925 0.68666667
11: 0.000000 5.756463 0.66000000
12: 5.756463 -11.512925 0.22666667
13: 5.756463 11.512925 0.68666667
14: -11.512925 5.756463 0.69333333
15: 5.756463 5.756463 0.66000000
16: 5.756463 -5.756463 0.05333333
17: 11.512925 -11.512925 0.05333333
18: -5.756463 5.756463 0.69333333
19: -11.512925 -11.512925 0.58666667
20: 11.512925 0.000000 0.06000000
21: -5.756463 11.512925 0.69333333
22: -11.512925 11.512925 0.69333333
23: -5.756463 -11.512925 0.58666667
24: -11.512925 -5.756463 0.58666667
25: 0.000000 11.512925 0.68666667
cost gamma classif.ce
<num> <num> <num>We plot the performances depending on the evaluated cost and gamma values.
library(ggplot2)
library(scales)
autoplot(instance, type = "points", cols_x = c("cost", "gamma")) +
scale_x_continuous(
trans = log2_trans(),
breaks = trans_breaks("log10", function(x) 10^x),
labels = trans_format("log10", math_format(10^.x))) +
scale_y_continuous(
trans = log2_trans(),
breaks = trans_breaks("log10", function(x) 10^x),
labels = trans_format("log10", math_format(10^.x)))Warning in transformation$transform(x): NaNs producedWarning in scale_x_continuous(trans = log2_trans(), breaks = trans_breaks("log10", : log-2 transformation introduced
infinite values.Warning in transformation$transform(x): NaNs producedWarning in scale_y_continuous(trans = log2_trans(), breaks = trans_breaks("log10", : log-2 transformation introduced
infinite values.Warning: Removed 16 rows containing missing values or values outside the scale range (`geom_point()`).
Dependencies ensure that certain parameters are only proposed depending on values of other hyperparameters. We want to tune the degree hyperparameter that is only needed for the polynomial kernel.
learner = lrn("classif.svm", type = "C-classification")
learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
learner$param_set$values$kernel = to_tune(c("polynomial", "radial"))
learner$param_set$values$degree = to_tune(1, 4)The dependencies are already stored in the learner parameter set.
learner$param_set$depsIndices: <id>, <on__id>
id on cond
<char> <char> <list>
1: coef0 kernel <Condition:CondAnyOf>
2: cost type <Condition:CondEqual>
3: degree kernel <Condition:CondEqual>
4: gamma kernel <Condition:CondAnyOf>
5: nu type <Condition:CondEqual>The gamma hyperparameter depends on the kernel being polynomial, radial or sigmoid
learner$param_set$deps$cond[[5]]CondEqual: x == nu-classificationwhereas the degree hyperparameter is solely used by the polynomial kernel.
learner$param_set$deps$cond[[3]]CondEqual: x == polynomialWe preview the grid to show the effect of the dependencies.
generate_design_grid(learner$param_set$search_space(), resolution = 2)<Design> with 12 rows:
cost degree gamma kernel
<num> <int> <num> <char>
1: -11.51293 1 -11.51293 polynomial
2: -11.51293 NA -11.51293 radial
3: -11.51293 1 11.51293 polynomial
4: -11.51293 NA 11.51293 radial
5: -11.51293 4 -11.51293 polynomial
6: -11.51293 4 11.51293 polynomial
7: 11.51293 1 -11.51293 polynomial
8: 11.51293 NA -11.51293 radial
9: 11.51293 1 11.51293 polynomial
10: 11.51293 NA 11.51293 radial
11: 11.51293 4 -11.51293 polynomial
12: 11.51293 4 11.51293 polynomialThe value for degree is NA if the dependency on the kernel is not satisfied.
We use the tune()-shortcut to run the tuning.
instance = tune(
tuner = tnr("grid_search", resolution = 3),
task = task,
learner = learner,
resampling = resampling,
measure = measure
)instance$result cost degree gamma kernel learner_param_vals x_domain classif.ce
<num> <int> <num> <char> <list> <list> <num>
1: 11.51293 1 -11.51293 polynomial <list[5]> <list[4]> 0.02We add the optimized hyperparameters to the learner and train the learner on the full dataset.
learner = lrn("classif.svm")
learner$param_set$values = instance$result_learner_param_vals
learner$train(task)The trained model can now be used to make predictions on new data. A common mistake is to report the performance estimated on the resampling sets on which the tuning was performed (instance$result_y) as the model’s performance. These scores might be biased and overestimate the ability of the fitted model to predict with new data. Instead, we have to use nested resampling to get an unbiased performance estimate.
Tuning should not be performed on the same resampling sets which are used for evaluating the model itself, since this would result in a biased performance estimate. Nested resampling uses an outer and inner resampling to separate the tuning from the performance estimation of the model. We can use the AutoTuner class for running nested resampling. The AutoTuner wraps a Learner and tunes the hyperparameter of the learner during $train(). This is our inner resampling loop.
learner = lrn("classif.svm", type = "C-classification")
learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
learner$param_set$values$kernel = to_tune(c("polynomial", "radial"))
learner$param_set$values$degree = to_tune(1, 4)
resampling_inner = rsmp("cv", folds = 3)
terminator = trm("none")
tuner = tnr("grid_search", resolution = 3)
at = auto_tuner(
learner = learner,
resampling = resampling_inner,
measure = measure,
terminator = terminator,
tuner = tuner,
store_models = TRUE)We put the AutoTuner into a resample() call to get the outer resampling loop.
resampling_outer = rsmp("cv", folds = 3)
rr = resample(task = task, learner = at, resampling = resampling_outer, store_models = TRUE)We check the inner tuning results for stable hyperparameters. This means that the selected hyperparameters should not vary too much. We might observe unstable models in this example because the small data set and the low number of resampling iterations might introduce too much randomness. Usually, we aim for the selection of stable hyperparameters for all outer training sets.
extract_inner_tuning_results(rr)[, .SD, .SDcols = !c("learner_param_vals", "x_domain")] iteration cost degree gamma kernel classif.ce task_id learner_id resampling_id
<int> <num> <int> <num> <char> <num> <char> <char> <char>
1: 1 0.00000 3 0.00000 polynomial 0.03980986 iris classif.svm.tuned cv
2: 2 0.00000 NA 0.00000 radial 0.02970885 iris classif.svm.tuned cv
3: 3 -11.51293 1 11.51293 polynomial 0.03000594 iris classif.svm.tuned cvNext, we want to compare the predictive performances estimated on the outer resampling to the inner resampling (extract_inner_tuning_results(rr)). Significantly lower predictive performances on the outer resampling indicate that the models with the optimized hyperparameters overfit the data.
rr$score()[, .(iteration, task_id, learner_id, resampling_id, classif.ce)] iteration task_id learner_id resampling_id classif.ce
<int> <char> <char> <char> <num>
1: 1 iris classif.svm.tuned cv 0.06
2: 2 iris classif.svm.tuned cv 0.08
3: 3 iris classif.svm.tuned cv 0.00The archives of the AutoTuners allows us to inspect all evaluated hyperparameters configurations with the associated predictive performances.
extract_inner_tuning_archives(rr, unnest = NULL, exclude_columns = c("resample_result", "uhash", "x_domain", "timestamp")) iteration cost degree gamma kernel classif.ce runtime_learners warnings errors batch_nr task_id
<int> <num> <int> <num> <char> <num> <num> <int> <int> <int> <char>
1: 1 0.00000 NA -11.51293 radial 0.69994058 0.017 0 0 1 iris
2: 1 11.51293 NA -11.51293 radial 0.04991087 0.020 0 0 2 iris
3: 1 0.00000 4 11.51293 polynomial 0.22846108 0.081 0 0 3 iris
4: 1 0.00000 3 0.00000 polynomial 0.03980986 0.012 0 0 4 iris
5: 1 0.00000 1 -11.51293 polynomial 0.69994058 0.015 0 0 5 iris
---
104: 3 11.51293 NA 11.51293 radial 0.64022579 0.016 0 0 32 iris
105: 3 11.51293 1 -11.51293 polynomial 0.03000594 0.013 0 0 33 iris
106: 3 -11.51293 3 -11.51293 polynomial 0.58140226 0.022 0 0 34 iris
107: 3 11.51293 3 11.51293 polynomial 0.09031491 0.013 0 0 35 iris
108: 3 11.51293 1 0.00000 polynomial 0.07040998 0.023 0 0 36 iris
learner_id resampling_id
<char> <char>
1: classif.svm.tuned cv
2: classif.svm.tuned cv
3: classif.svm.tuned cv
4: classif.svm.tuned cv
5: classif.svm.tuned cv
---
104: classif.svm.tuned cv
105: classif.svm.tuned cv
106: classif.svm.tuned cv
107: classif.svm.tuned cv
108: classif.svm.tuned cvThe aggregated performance of all outer resampling iterations is essentially the unbiased performance of an SVM with optimal hyperparameter found by grid search.
rr$aggregate()classif.ce
0.04666667 Applying nested resampling can be shortened by using the tune_nested()-shortcut.
learner = lrn("classif.svm", type = "C-classification")
learner$param_set$values$cost = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
learner$param_set$values$gamma = to_tune(p_dbl(1e-5, 1e5, logscale = TRUE))
learner$param_set$values$kernel = to_tune(c("polynomial", "radial"))
learner$param_set$values$degree = to_tune(1, 4)
rr = tune_nested(
tuner = tnr("grid_search", resolution = 3),
task = tsk("iris"),
learner = learner,
inner_resampling = rsmp ("cv", folds = 3),
outer_resampling = rsmp("cv", folds = 3),
measure = msr("classif.ce"),
)The mlr3book includes chapters on tuning spaces and hyperparameter tuning. The mlr3cheatsheets contain frequently used commands and workflows of mlr3.
sessioninfo::session_info(info = "packages")═ Session info ═══════════════════════════════════════════════════════════════════════════════════════════════════════
─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
backports 1.5.0 2024-05-23 [1] RSPM
base64enc 0.1-6 2026-02-02 [1] RSPM
bbotk 1.8.1 2025-11-26 [1] RSPM
checkmate 2.3.4 2026-02-03 [1] RSPM
class 7.3-23 2025-01-01 [2] CRAN (R 4.5.2)
cli 3.6.5 2025-04-23 [1] RSPM
cluster 2.1.8.1 2025-03-12 [2] CRAN (R 4.5.2)
codetools 0.2-20 2024-03-31 [2] CRAN (R 4.5.2)
crayon 1.5.3 2024-06-20 [1] RSPM
data.table * 1.18.2.1 2026-01-27 [1] RSPM
DEoptimR 1.1-4 2025-07-27 [1] RSPM
DiceKriging 1.6.1 2025-10-21 [1] RSPM
digest 0.6.39 2025-11-19 [1] RSPM
diptest 0.77-2 2025-08-20 [1] RSPM
dplyr 1.2.0 2026-02-03 [1] RSPM
e1071 1.7-17 2025-12-18 [1] RSPM
evaluate 1.0.5 2025-08-27 [1] RSPM
farver 2.1.2 2024-05-13 [1] RSPM
fastmap 1.2.0 2024-05-15 [1] RSPM
flexmix 2.3-20 2025-02-28 [1] RSPM
fpc 2.2-14 2026-01-14 [1] RSPM
future 1.69.0 2026-01-16 [1] RSPM
future.apply 1.20.2 2026-02-20 [1] RSPM
generics 0.1.4 2025-05-09 [1] RSPM
ggplot2 * 4.0.2 2026-02-03 [1] RSPM
globals 0.19.0 2026-02-02 [1] RSPM
glue 1.8.0 2024-09-30 [1] RSPM
gtable 0.3.6 2024-10-25 [1] RSPM
htmltools 0.5.9 2025-12-04 [1] RSPM
htmlwidgets 1.6.4 2023-12-06 [1] RSPM
jsonlite 2.0.0 2025-03-27 [1] RSPM
kernlab 0.9-33 2024-08-13 [1] RSPM
knitr 1.51 2025-12-20 [1] RSPM
labeling 0.4.3 2023-08-29 [1] RSPM
lattice 0.22-7 2025-04-02 [2] CRAN (R 4.5.2)
lgr 0.5.2 2026-01-30 [1] RSPM
lifecycle 1.0.5 2026-01-08 [1] RSPM
listenv 0.10.0 2025-11-02 [1] RSPM
magrittr 2.0.4 2025-09-12 [1] RSPM
MASS 7.3-65 2025-02-28 [2] CRAN (R 4.5.2)
Matrix 1.7-4 2025-08-28 [2] CRAN (R 4.5.2)
mclust 6.1.2 2025-10-31 [1] RSPM
mlr3 * 1.4.0 2026-02-19 [1] RSPM
mlr3cluster 0.2.0 2026-02-04 [1] RSPM
mlr3cmprsk 0.0.1 2026-02-27 [1] Github (mlr-org/mlr3cmprsk@5a04c29)
mlr3data 0.9.0 2024-11-08 [1] RSPM
mlr3extralearners 1.4.0 2026-01-26 [1] https://m~
mlr3filters 0.9.0 2025-09-12 [1] RSPM
mlr3fselect 1.5.0 2025-11-27 [1] RSPM
mlr3hyperband 1.0.0 2025-07-10 [1] RSPM
mlr3inferr 0.2.1 2025-11-26 [1] RSPM
mlr3learners 0.14.0 2025-12-13 [1] RSPM
mlr3mbo 0.3.3 2025-10-10 [1] RSPM
mlr3measures 1.2.0 2025-11-25 [1] RSPM
mlr3misc 0.21.0 2026-02-26 [1] RSPM
mlr3pipelines 0.10.0 2025-11-07 [1] RSPM
mlr3tuning 1.5.1 2025-12-14 [1] RSPM
mlr3tuningspaces 0.6.0 2025-05-16 [1] RSPM
mlr3verse * 0.3.1 2025-01-14 [1] RSPM
mlr3viz 0.11.0 2026-02-22 [1] RSPM
mlr3website * 0.0.0.9000 2026-02-27 [1] Github (mlr-org/mlr3website@f6e32a7)
modeltools 0.2-24 2025-05-02 [1] RSPM
nnet 7.3-20 2025-01-01 [2] CRAN (R 4.5.2)
otel 0.2.0 2025-08-29 [1] RSPM
palmerpenguins 0.1.1 2022-08-15 [1] RSPM
paradox 1.0.1 2024-07-09 [1] RSPM
parallelly 1.46.1 2026-01-08 [1] RSPM
pillar 1.11.1 2025-09-17 [1] RSPM
pkgconfig 2.0.3 2019-09-22 [1] RSPM
prabclus 2.3-5 2026-01-14 [1] RSPM
proxy 0.4-29 2025-12-29 [1] RSPM
purrr 1.2.1 2026-01-09 [1] RSPM
R6 2.6.1 2025-02-15 [1] RSPM
RColorBrewer 1.1-3 2022-04-03 [1] RSPM
Rcpp 1.1.1 2026-01-10 [1] RSPM
repr 1.1.7 2024-03-22 [1] RSPM
rlang 1.1.7 2026-01-09 [1] RSPM
rmarkdown 2.30 2025-09-28 [1] RSPM
robustbase 0.99-7 2026-02-05 [1] RSPM
S7 0.2.1 2025-11-14 [1] RSPM
scales * 1.4.0 2025-04-24 [1] RSPM
sessioninfo 1.2.3 2025-02-05 [1] RSPM
skimr 2.2.2 2026-01-10 [1] RSPM
spacefillr 0.4.0 2025-02-24 [1] RSPM
stringi 1.8.7 2025-03-27 [1] RSPM
stringr 1.6.0 2025-11-04 [1] RSPM
survdistr 0.0.1 2026-02-27 [1] Github (mlr-org/survdistr@d7babd1)
survival 3.8-3 2024-12-17 [2] CRAN (R 4.5.2)
tibble 3.3.1 2026-01-11 [1] RSPM
tidyr 1.3.2 2025-12-19 [1] RSPM
tidyselect 1.2.1 2024-03-11 [1] RSPM
uuid 1.2-2 2026-01-23 [1] RSPM
vctrs 0.7.1 2026-01-23 [1] RSPM
viridisLite 0.4.3 2026-02-04 [1] RSPM
withr 3.0.2 2024-10-28 [1] RSPM
xfun 0.56 2026-01-18 [1] RSPM
yaml 2.3.12 2025-12-10 [1] RSPM
[1] /usr/local/lib/R/site-library
[2] /usr/local/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────