library(mlr3verse)Scope
This is the third part of the practical tuning series. The other parts can be found here:
- Part I - Tune a Support Vector Machine
- Part II - Tune a Preprocessing Pipeline
- Part IV - Tuning and Parallel Processing
In this post, we implement a simple automated machine learning (AutoML) system which includes preprocessing, a switch between multiple learners and hyperparameter tuning. For this, we build a pipeline with the mlr3pipelines extension package. Additionally, we use nested resampling to get an unbiased performance estimate of our AutoML system.
Prerequisites
We load the mlr3verse package which pulls in the most important packages for this example.
We initialize the random number generator with a fixed seed for reproducibility, and decrease the verbosity of the logger to keep the output clearly represented. The lgr package is used for logging in all mlr3 packages. The mlr3 logger prints the logging messages from the base package, whereas the bbotk logger is responsible for logging messages from the optimization packages (e.g. mlr3tuning ).
set.seed(7832)
lgr::get_logger("mlr3")$set_threshold("warn")
lgr::get_logger("bbotk")$set_threshold("warn")In this example, we use the Pima Indians Diabetes data set which is used to to predict whether or not a patient has diabetes. The patients are characterized by 8 numeric features and some have missing values.
task = tsk("pima")Branching
We use three popular machine learning algorithms: k-nearest-neighbors, support vector machines and random forests.
learners = list(
lrn("classif.kknn", id = "kknn"),
lrn("classif.svm", id = "svm", type = "C-classification"),
lrn("classif.ranger", id = "ranger")
)The PipeOpBranch allows us to specify multiple alternatives paths. In this graph, the paths lead to the different learner models. The selection hyperparameter controls which path is executed i.e., which learner is used to fit a model. It is important to use the PipeOpBranch after the branching so that the outputs are merged into one result object. We visualize the graph with branching below.
graph =
po("branch", options = c("kknn", "svm", "ranger")) %>>%
gunion(lapply(learners, po)) %>>%
po("unbranch")
graph$plot(html = FALSE)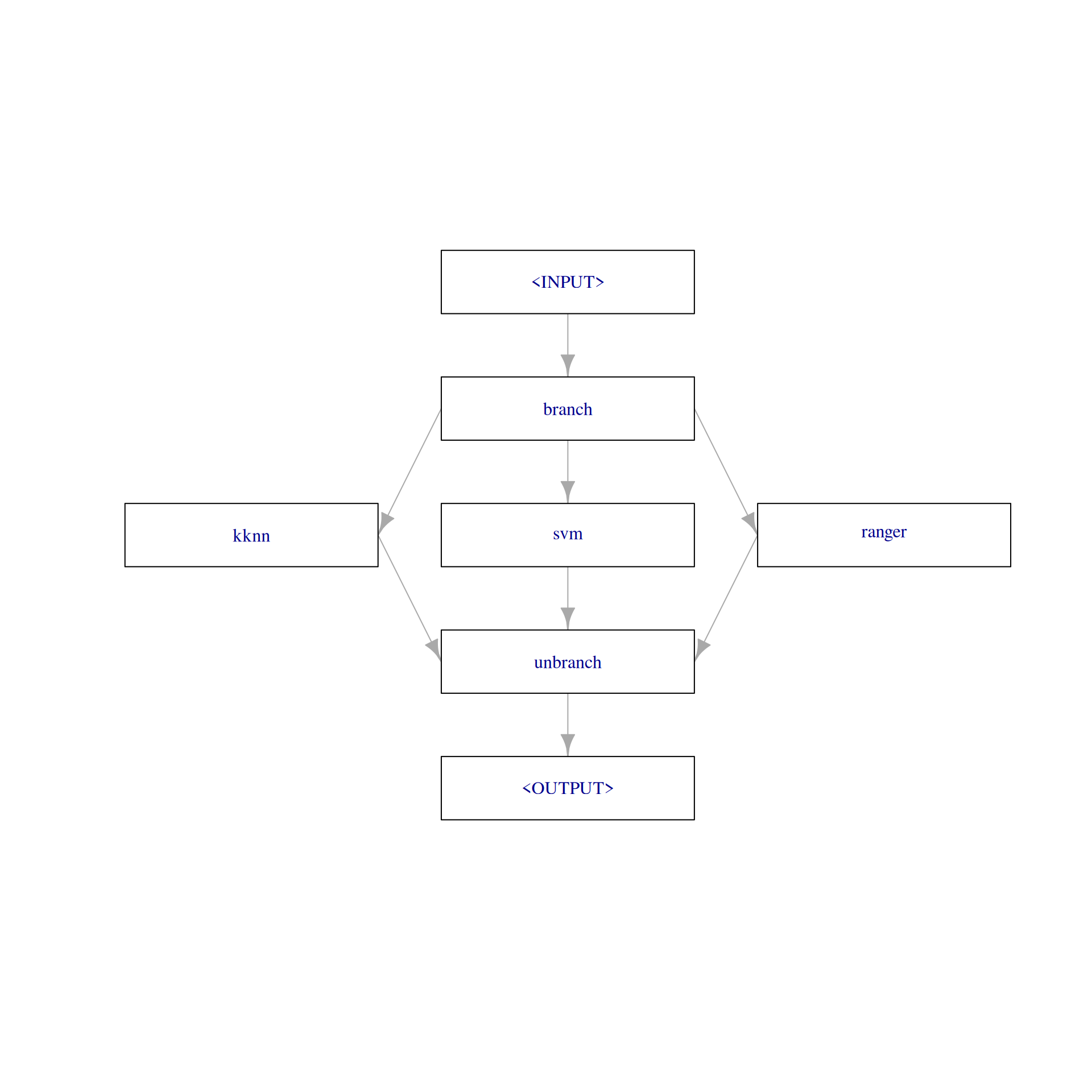
Alternatively, we can use the ppl()-shortcut to load a predefined graph from the mlr_graphs dictionary. For this, the learner list must be named.
learners = list(
kknn = lrn("classif.kknn", id = "kknn"),
svm = lrn("classif.svm", id = "svm", type = "C-classification"),
ranger = lrn("classif.ranger", id = "ranger")
)
graph = ppl("branch", lapply(learners, po))Preprocessing
The task has missing data in five columns.
round(task$missings() / task$nrow, 2)diabetes age glucose insulin mass pedigree pregnant pressure triceps
0.00 0.00 0.01 0.49 0.01 0.00 0.00 0.05 0.30 The pipeline "robustify" function creates a preprocessing pipeline based on our task. The resulting pipeline imputes missing values with PipeOpImputeHist and creates a dummy column (PipeOpMissInd) which indicates the imputed missing values. Internally, this creates two paths and the results are combined with PipeOpFeatureUnion. In contrast to PipeOpBranch, both paths are executed. Additionally, "robustify" adds PipeOpEncode to encode factor columns and PipeOpRemoveConstants to remove features with a constant value.
graph = ppl("robustify", task = task, factors_to_numeric = TRUE) %>>%
graph
plot(graph, html = FALSE)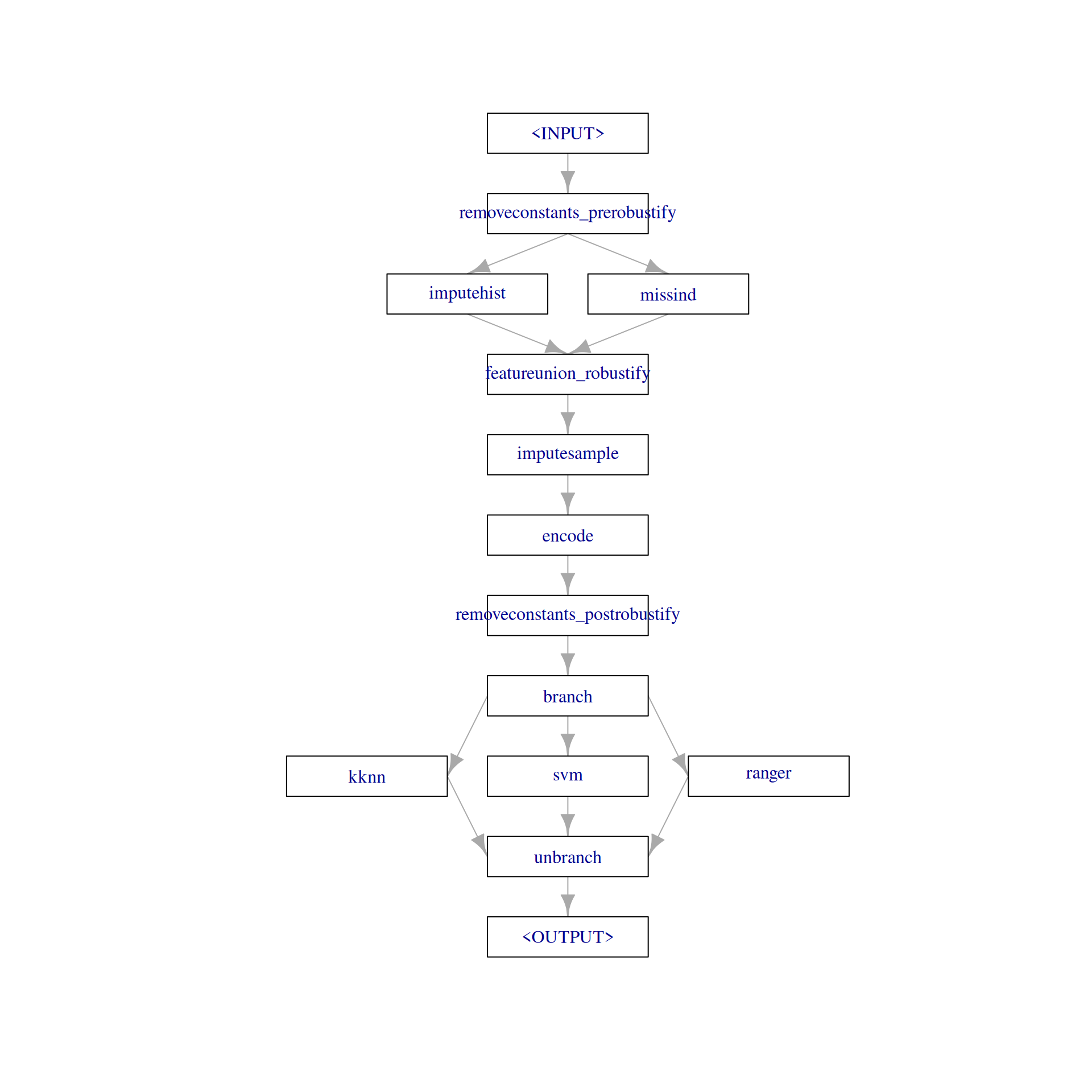
We could also create the preprocessing pipeline manually.
gunion(list(po("imputehist"),
po("missind", affect_columns = selector_type(c("numeric", "integer"))))) %>>%
po("featureunion") %>>%
po("encode") %>>%
po("removeconstants")
── Graph with 5 PipeOps: ───────────────────────────────────────────────────────────────────────────────────────────────
ID State sccssors prdcssors
<char> <char> <char> <char>
imputehist <<UNTRAINED>> featureunion
missind <<UNTRAINED>> featureunion
featureunion <<UNTRAINED>> encode imputehist,missind
encode <<UNTRAINED>> removeconstants featureunion
removeconstants <<UNTRAINED>> encode
── Pipeline: non-sequential Graph Learner
We use as_learner() to create a GraphLearner which encapsulates the pipeline and can be used like a learner.
graph_learner = as_learner(graph)The parameter set of the graph learner includes all hyperparameters from all contained learners. The hyperparameter ids are prefixed with the corresponding learner ids. The hyperparameter branch.selection controls which learner is used.
as.data.table(graph_learner$param_set)[, .(id, class, lower, upper, nlevels)] id class lower upper nlevels
<char> <char> <num> <num> <num>
1: removeconstants_prerobustify.ratio ParamDbl 0 1 Inf
2: removeconstants_prerobustify.rel_tol ParamDbl 0 Inf Inf
3: removeconstants_prerobustify.abs_tol ParamDbl 0 Inf Inf
4: removeconstants_prerobustify.na_ignore ParamLgl NA NA 2
5: removeconstants_prerobustify.affect_columns ParamUty NA NA Inf
6: imputehist.affect_columns ParamUty NA NA Inf
7: missind.which ParamFct NA NA 2
8: missind.type ParamFct NA NA 4
9: missind.affect_columns ParamUty NA NA Inf
10: imputesample.affect_columns ParamUty NA NA Inf
11: encode.method ParamFct NA NA 5
12: encode.affect_columns ParamUty NA NA Inf
13: removeconstants_postrobustify.ratio ParamDbl 0 1 Inf
14: removeconstants_postrobustify.rel_tol ParamDbl 0 Inf Inf
15: removeconstants_postrobustify.abs_tol ParamDbl 0 Inf Inf
16: removeconstants_postrobustify.na_ignore ParamLgl NA NA 2
17: removeconstants_postrobustify.affect_columns ParamUty NA NA Inf
18: kknn.k ParamInt 1 Inf Inf
19: kknn.distance ParamDbl 0 Inf Inf
20: kknn.kernel ParamFct NA NA 10
21: kknn.scale ParamLgl NA NA 2
22: kknn.ykernel ParamUty NA NA Inf
23: kknn.store_model ParamLgl NA NA 2
24: svm.cachesize ParamDbl -Inf Inf Inf
25: svm.class.weights ParamUty NA NA Inf
26: svm.coef0 ParamDbl -Inf Inf Inf
27: svm.cost ParamDbl 0 Inf Inf
28: svm.cross ParamInt 0 Inf Inf
29: svm.decision.values ParamLgl NA NA 2
30: svm.degree ParamInt 1 Inf Inf
31: svm.epsilon ParamDbl 0 Inf Inf
32: svm.fitted ParamLgl NA NA 2
33: svm.gamma ParamDbl 0 Inf Inf
34: svm.kernel ParamFct NA NA 4
35: svm.nu ParamDbl -Inf Inf Inf
36: svm.scale ParamUty NA NA Inf
37: svm.shrinking ParamLgl NA NA 2
38: svm.tolerance ParamDbl 0 Inf Inf
39: svm.type ParamFct NA NA 2
40: ranger.always.split.variables ParamUty NA NA Inf
41: ranger.class.weights ParamUty NA NA Inf
42: ranger.holdout ParamLgl NA NA 2
43: ranger.importance ParamFct NA NA 4
44: ranger.keep.inbag ParamLgl NA NA 2
45: ranger.max.depth ParamInt 1 Inf Inf
46: ranger.min.bucket ParamUty NA NA Inf
47: ranger.min.node.size ParamUty NA NA Inf
48: ranger.mtry ParamInt 1 Inf Inf
49: ranger.mtry.ratio ParamDbl 0 1 Inf
50: ranger.na.action ParamFct NA NA 3
51: ranger.num.random.splits ParamInt 1 Inf Inf
52: ranger.node.stats ParamLgl NA NA 2
53: ranger.num.threads ParamInt 1 Inf Inf
54: ranger.num.trees ParamInt 1 Inf Inf
55: ranger.oob.error ParamLgl NA NA 2
56: ranger.regularization.factor ParamUty NA NA Inf
57: ranger.regularization.usedepth ParamLgl NA NA 2
58: ranger.replace ParamLgl NA NA 2
59: ranger.respect.unordered.factors ParamFct NA NA 3
60: ranger.sample.fraction ParamDbl 0 1 Inf
61: ranger.save.memory ParamLgl NA NA 2
62: ranger.scale.permutation.importance ParamLgl NA NA 2
63: ranger.seed ParamInt -Inf Inf Inf
64: ranger.split.select.weights ParamUty NA NA Inf
65: ranger.splitrule ParamFct NA NA 3
66: ranger.verbose ParamLgl NA NA 2
67: ranger.write.forest ParamLgl NA NA 2
68: branch.selection ParamFct NA NA 3
id class lower upper nlevels
<char> <char> <num> <num> <num>Tune the pipeline
We will only tune one hyperparameter for each learner in this example. Additionally, we tune the branching parameter which selects one of the three learners. We have to specify that a hyperparameter is only valid for a certain learner by using depends = branch.selection == <learner_id>.
# branch
graph_learner$param_set$values$branch.selection =
to_tune(c("kknn", "svm", "ranger"))
# kknn
graph_learner$param_set$values$kknn.k =
to_tune(p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"))
# svm
graph_learner$param_set$values$svm.cost =
to_tune(p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"))
# ranger
graph_learner$param_set$values$ranger.mtry =
to_tune(p_int(1, 8, depends = branch.selection == "ranger"))
# short learner id for printing
graph_learner$id = "graph_learner"We define a tuning instance and select a random search which is stopped after 20 evaluated configurations.
instance = tune(
tuner = tnr("random_search"),
task = task,
learner = graph_learner,
resampling = rsmp("cv", folds = 3),
measure = msr("classif.ce"),
term_evals = 20
)The following shows a quick way to visualize the tuning results.
autoplot(instance, type = "marginal",
cols_x = c("kknn.k", "svm.cost", "ranger.mtry"))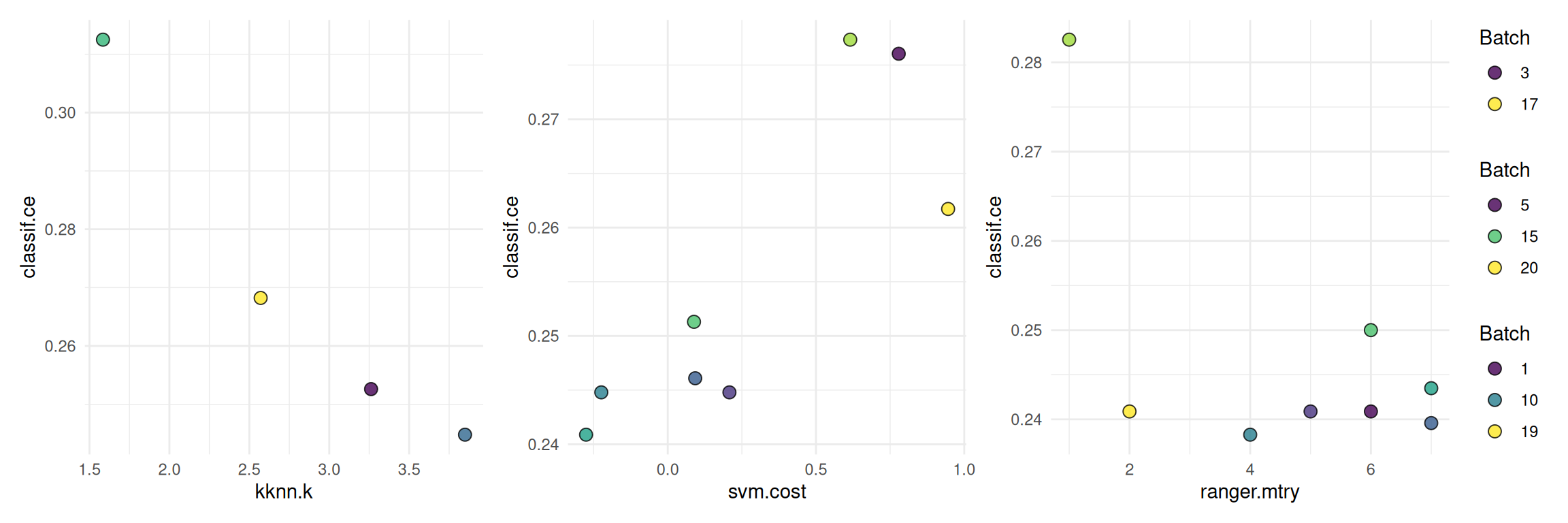
Final Model
We add the optimized hyperparameters to the graph learner and train the learner on the full dataset.
learner = as_learner(graph)
learner$param_set$values = instance$result_learner_param_vals
learner$train(task)The trained model can now be used to make predictions on new data. A common mistake is to report the performance estimated on the resampling sets on which the tuning was performed (instance$result_y) as the model’s performance. Instead we have to use nested resampling to get an unbiased performance estimate.
Nested Resampling
We use nested resampling to get an unbiased estimate of the predictive performance of our graph learner.
graph_learner = as_learner(graph)
graph_learner$param_set$values$branch.selection =
to_tune(c("kknn", "svm", "ranger"))
graph_learner$param_set$values$kknn.k =
to_tune(p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"))
graph_learner$param_set$values$svm.cost =
to_tune(p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"))
graph_learner$param_set$values$ranger.mtry =
to_tune(p_int(1, 8, depends = branch.selection == "ranger"))
graph_learner$id = "graph_learner"
inner_resampling = rsmp("cv", folds = 3)
at = auto_tuner(
learner = graph_learner,
resampling = inner_resampling,
measure = msr("classif.ce"),
terminator = trm("evals", n_evals = 10),
tuner = tnr("random_search")
)
outer_resampling = rsmp("cv", folds = 3)
rr = resample(task, at, outer_resampling, store_models = TRUE)We check the inner tuning results for stable hyperparameters. This means that the selected hyperparameters should not vary too much. We might observe unstable models in this example because the small data set and the low number of resampling iterations might introduce too much randomness. Usually, we aim for the selection of stable hyperparameters for all outer training sets.
extract_inner_tuning_results(rr)Next, we want to compare the predictive performances estimated on the outer resampling to the inner resampling. Significantly lower predictive performances on the outer resampling indicate that the models with the optimized hyperparameters overfit the data.
rr$score()[, .(iteration, task_id, learner_id, resampling_id, classif.ce)] iteration task_id learner_id resampling_id classif.ce
<int> <char> <char> <char> <num>
1: 1 pima graph_learner.tuned cv 0.2695312
2: 2 pima graph_learner.tuned cv 0.2578125
3: 3 pima graph_learner.tuned cv 0.2343750The aggregated performance of all outer resampling iterations is essentially the unbiased performance of the graph learner with optimal hyperparameter found by random search.
rr$aggregate()classif.ce
0.2539062 Applying nested resampling can be shortened by using the tune_nested()-shortcut.
graph_learner = as_learner(graph)
graph_learner$param_set$values$branch.selection =
to_tune(c("kknn", "svm", "ranger"))
graph_learner$param_set$values$kknn.k =
to_tune(p_int(3, 50, logscale = TRUE, depends = branch.selection == "kknn"))
graph_learner$param_set$values$svm.cost =
to_tune(p_dbl(-1, 1, trafo = function(x) 10^x, depends = branch.selection == "svm"))
graph_learner$param_set$values$ranger.mtry =
to_tune(p_int(1, 8, depends = branch.selection == "ranger"))
graph_learner$id = "graph_learner"
rr = tune_nested(
tuner = tnr("random_search"),
task = task,
learner = graph_learner,
inner_resampling = rsmp("cv", folds = 3),
outer_resampling = rsmp("cv", folds = 3),
measure = msr("classif.ce"),
term_evals = 10,
)Resources
The mlr3book includes chapters on pipelines and hyperparameter tuning. The mlr3cheatsheets contain frequently used commands and workflows of mlr3.
Session Information
sessioninfo::session_info(info = "packages")═ Session info ═══════════════════════════════════════════════════════════════════════════════════════════════════════
─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
backports 1.5.0 2024-05-23 [1] RSPM
bbotk 1.8.1 2025-11-26 [1] RSPM
bslib 0.10.0 2026-01-26 [1] RSPM
cachem 1.1.0 2024-05-16 [1] RSPM
checkmate 2.3.4 2026-02-03 [1] RSPM
class 7.3-23 2025-01-01 [2] CRAN (R 4.5.2)
cli 3.6.5 2025-04-23 [1] RSPM
cluster 2.1.8.1 2025-03-12 [2] CRAN (R 4.5.2)
codetools 0.2-20 2024-03-31 [2] CRAN (R 4.5.2)
crayon 1.5.3 2024-06-20 [1] RSPM
crosstalk 1.2.2 2025-08-26 [1] RSPM
data.table * 1.18.2.1 2026-01-27 [1] RSPM
DEoptimR 1.1-4 2025-07-27 [1] RSPM
digest 0.6.39 2025-11-19 [1] RSPM
diptest 0.77-2 2025-08-20 [1] RSPM
dplyr 1.2.0 2026-02-03 [1] RSPM
DT 0.34.0 2025-09-02 [1] RSPM
e1071 1.7-17 2025-12-18 [1] RSPM
evaluate 1.0.5 2025-08-27 [1] RSPM
farver 2.1.2 2024-05-13 [1] RSPM
fastmap 1.2.0 2024-05-15 [1] RSPM
flexmix 2.3-20 2025-02-28 [1] RSPM
fpc 2.2-14 2026-01-14 [1] RSPM
future 1.69.0 2026-01-16 [1] RSPM
future.apply 1.20.2 2026-02-20 [1] RSPM
generics 0.1.4 2025-05-09 [1] RSPM
ggplot2 4.0.2 2026-02-03 [1] RSPM
globals 0.19.0 2026-02-02 [1] RSPM
glue 1.8.0 2024-09-30 [1] RSPM
gtable 0.3.6 2024-10-25 [1] RSPM
htmltools 0.5.9 2025-12-04 [1] RSPM
htmlwidgets 1.6.4 2023-12-06 [1] RSPM
igraph 2.2.2 2026-02-12 [1] RSPM
jquerylib 0.1.4 2021-04-26 [1] RSPM
jsonlite 2.0.0 2025-03-27 [1] RSPM
kernlab 0.9-33 2024-08-13 [1] RSPM
kknn 1.4.1 2025-05-19 [1] RSPM
knitr 1.51 2025-12-20 [1] RSPM
labeling 0.4.3 2023-08-29 [1] RSPM
lattice 0.22-7 2025-04-02 [2] CRAN (R 4.5.2)
lgr 0.5.2 2026-01-30 [1] RSPM
lifecycle 1.0.5 2026-01-08 [1] RSPM
listenv 0.10.0 2025-11-02 [1] RSPM
magrittr 2.0.4 2025-09-12 [1] RSPM
MASS 7.3-65 2025-02-28 [2] CRAN (R 4.5.2)
Matrix 1.7-4 2025-08-28 [2] CRAN (R 4.5.2)
mclust 6.1.2 2025-10-31 [1] RSPM
mlr3 * 1.4.0 2026-02-19 [1] RSPM
mlr3cluster 0.2.0 2026-02-04 [1] RSPM
mlr3cmprsk 0.0.1 2026-02-27 [1] Github (mlr-org/mlr3cmprsk@5a04c29)
mlr3data 0.9.0 2024-11-08 [1] RSPM
mlr3extralearners 1.4.0 2026-01-26 [1] https://m~
mlr3filters 0.9.0 2025-09-12 [1] RSPM
mlr3fselect 1.5.0 2025-11-27 [1] RSPM
mlr3hyperband 1.0.0 2025-07-10 [1] RSPM
mlr3inferr 0.2.1 2025-11-26 [1] RSPM
mlr3learners 0.14.0 2025-12-13 [1] RSPM
mlr3mbo 0.3.3 2025-10-10 [1] RSPM
mlr3measures 1.2.0 2025-11-25 [1] RSPM
mlr3misc 0.21.0 2026-02-26 [1] RSPM
mlr3pipelines 0.10.0 2025-11-07 [1] RSPM
mlr3tuning 1.5.1 2025-12-14 [1] RSPM
mlr3tuningspaces 0.6.0 2025-05-16 [1] RSPM
mlr3verse * 0.3.1 2025-01-14 [1] RSPM
mlr3viz 0.11.0 2026-02-22 [1] RSPM
mlr3website * 0.0.0.9000 2026-02-27 [1] Github (mlr-org/mlr3website@f6e32a7)
modeltools 0.2-24 2025-05-02 [1] RSPM
nnet 7.3-20 2025-01-01 [2] CRAN (R 4.5.2)
otel 0.2.0 2025-08-29 [1] RSPM
palmerpenguins 0.1.1 2022-08-15 [1] RSPM
paradox 1.0.1 2024-07-09 [1] RSPM
parallelly 1.46.1 2026-01-08 [1] RSPM
patchwork 1.3.2 2025-08-25 [1] RSPM
pillar 1.11.1 2025-09-17 [1] RSPM
pkgconfig 2.0.3 2019-09-22 [1] RSPM
prabclus 2.3-5 2026-01-14 [1] RSPM
proxy 0.4-29 2025-12-29 [1] RSPM
R6 2.6.1 2025-02-15 [1] RSPM
ranger 0.18.0 2026-01-16 [1] RSPM
RColorBrewer 1.1-3 2022-04-03 [1] RSPM
Rcpp 1.1.1 2026-01-10 [1] RSPM
rlang 1.1.7 2026-01-09 [1] RSPM
rmarkdown 2.30 2025-09-28 [1] RSPM
robustbase 0.99-7 2026-02-05 [1] RSPM
S7 0.2.1 2025-11-14 [1] RSPM
sass 0.4.10 2025-04-11 [1] RSPM
scales 1.4.0 2025-04-24 [1] RSPM
sessioninfo 1.2.3 2025-02-05 [1] RSPM
spacefillr 0.4.0 2025-02-24 [1] RSPM
stringi 1.8.7 2025-03-27 [1] RSPM
survdistr 0.0.1 2026-02-27 [1] Github (mlr-org/survdistr@d7babd1)
survival 3.8-3 2024-12-17 [2] CRAN (R 4.5.2)
tibble 3.3.1 2026-01-11 [1] RSPM
tidyselect 1.2.1 2024-03-11 [1] RSPM
uuid 1.2-2 2026-01-23 [1] RSPM
vctrs 0.7.1 2026-01-23 [1] RSPM
viridisLite 0.4.3 2026-02-04 [1] RSPM
withr 3.0.2 2024-10-28 [1] RSPM
xfun 0.56 2026-01-18 [1] RSPM
yaml 2.3.12 2025-12-10 [1] RSPM
[1] /usr/local/lib/R/site-library
[2] /usr/local/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────