
library(mlr3verse)
learner = lrn("classif.ranger",
mtry.ratio = to_tune(0, 1),
replace = to_tune(),
sample.fraction = to_tune(1e-1, 1),
num.trees = to_tune(1, 2000)
)Scope
Hotstarting a learner resumes the training from an already fitted model. An example would be to train an already fit XGBoost model for an additional 500 boosting iterations. In mlr3, we call this process Hotstarting, where a learner has access to a cache of already trained models which is called a mlr3::HoststartStack We distinguish between forward and backward hotstarting. We start this post with backward hotstarting and then talk about the less efficient forward hotstarting.
Backward Hotstarting
In this example, we optimize the hyperparameters of a random forest and use hotstarting to reduce the runtime. Hotstarting a random forest backwards is very simple. The model remains unchanged and only a subset of the trees is used for prediction i.e. a new model is not fitted. For example, a random forest is trained with 1000 trees and a specific hyperparameter configuration. If another random forest with 500 trees but with the same hyperparameter configuration has to be trained, the model with 1000 trees is copied and only 500 trees are used for prediction.
We load the ranger learner and set the search space from the Bischl et al. (2021) article.
We activate hotstarting with the allow_hotstart option. When running a grid search with hotstarting, the grid is sorted by the hot start parameter. This means the models with 2000 trees are trained first. The models with less than 2000 trees hot start on the 2000 trees models which allows the training to be completed immediately.
instance = tune(
tuner = tnr("grid_search", resolution = 5, batch_size = 5),
task = tsk("spam"),
learner = learner,
resampling = rsmp("holdout"),
measure = msr("classif.ce"),
allow_hotstart = TRUE
)For comparison, we perform the same tuning without hotstarting.
instance_2 = tune(
tuner = tnr("grid_search", resolution = 5, batch_size = 5),
task = tsk("spam"),
learner = learner,
resampling = rsmp("holdout"),
measure = msr("classif.ce"),
allow_hotstart = FALSE
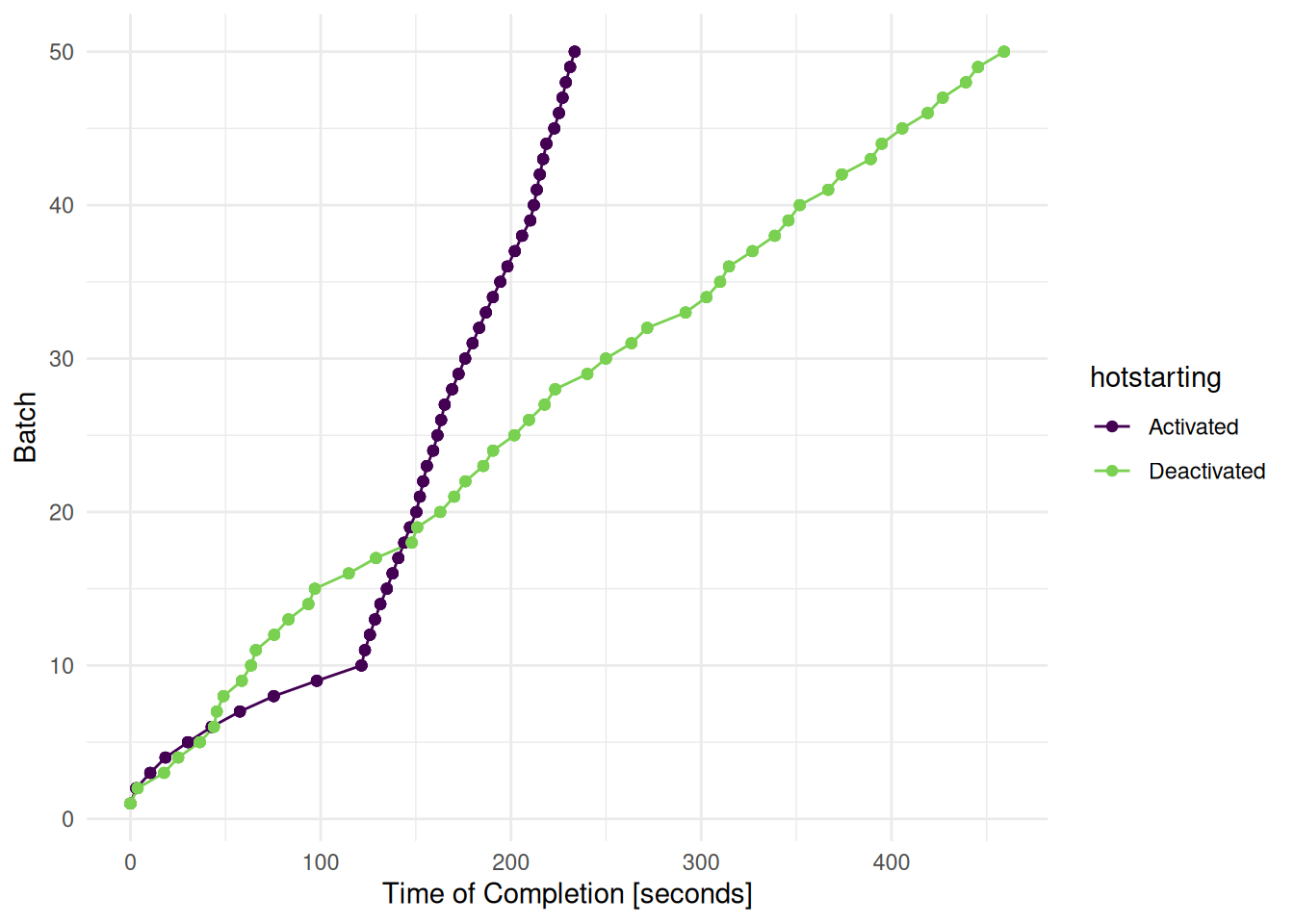
)We plot the time of completion of each batch (see Figure 1). Each batch includes 5 configurations. We can see that tuning with hotstarting is slower at first. As soon as all models are fitted with 2000 trees, the tuning runs much faster and overtakes the tuning without hotstarting.
Forward Hotstarting
Forward hotstarting is currently only supported by XGBoost. However, we have observed that hotstarting only provides a speed advantage for very large datasets and models with more than 5000 boosting rounds. The reason is that copying the models from the main process to the workers is a major bottleneck. The parallelization package future copies the models sequentially to the workers. Consequently, it takes a long time until the last worker can even start. Moreover, copying itself consumes a lot of time, and copying the model back from the worker blocks the main process again. During the development process, we overestimated the speed benefits of hotstarting and underestimated the overhead of parallelization. We can therefore only advise against using forward hotstarting during tuning. It is much more efficient to use the internal early-stopping mechanism of XGBoost. This eliminates the need to copy models to the worker. See the gallery post on early stopping for an example. We might improve the efficiency of the hotstarting mechanism in the future, if there are convincing use cases.
Manual Hotstarting
Nevertheless, forward hotstarting can be useful without parallelization. If you have an already trained model and want to add more boosting iteration to it. In this example, the learner_5000 is the already trained model. We create a new learner with the same hyperparameters but double the number of boosting iteration. To activate hotstarting, we create a HotstartStack and copy it to the $hotstart_stack slot of the new learner.
task = tsk("spam")
learner_5000 = lrn("classif.xgboost", nrounds = 5000, eta = 0.1)
learner_5000$train(task)
learner_10000 = lrn("classif.xgboost", nrounds = 10000, eta = 0.1)
learner_10000$hotstart_stack = HotstartStack$new(learner_5000)
learner_10000$train(task)Training the initial model took 59.885 seconds.
learner_5000$state$train_time[1] 59.885Adding 5000 boosting rounds took 46.837 seconds.
learner_10000$state$train_time - learner_5000$state$train_time[1] 46.837Training the model from the beginning would have taken about two minutes. This means, without parallelization, we get the expected speed advantage.
Conclusion
We have seen how mlr3 enables to reduce the training time, by building on a hotstart stack of already trained learners. One has to be careful, however, when using forward hotstarting during tuning because of the high parallelization overhead that arises from copying the models between the processes. If a model has an internal early stopping implementation, it should usually be relied upon instead of using the mlr3 hotstarting mechanism. However, manual forward hotstarting can be helpful in some situations when we do not want to train a large model from the beginning.
Session Information
sessioninfo::session_info(info = "packages")═ Session info ═══════════════════════════════════════════════════════════════════════════════════════════════════════
─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
backports 1.5.0 2024-05-23 [1] RSPM
bbotk 1.8.1 2025-11-26 [1] RSPM
checkmate 2.3.4 2026-02-03 [1] RSPM
class 7.3-23 2025-01-01 [2] CRAN (R 4.5.2)
cli 3.6.5 2025-04-23 [1] RSPM
cluster 2.1.8.1 2025-03-12 [2] CRAN (R 4.5.2)
codetools 0.2-20 2024-03-31 [2] CRAN (R 4.5.2)
crayon 1.5.3 2024-06-20 [1] RSPM
data.table * 1.18.2.1 2026-01-27 [1] RSPM
DEoptimR 1.1-4 2025-07-27 [1] RSPM
digest 0.6.39 2025-11-19 [1] RSPM
diptest 0.77-2 2025-08-20 [1] RSPM
dplyr 1.2.0 2026-02-03 [1] RSPM
evaluate 1.0.5 2025-08-27 [1] RSPM
farver 2.1.2 2024-05-13 [1] RSPM
fastmap 1.2.0 2024-05-15 [1] RSPM
flexmix 2.3-20 2025-02-28 [1] RSPM
fpc 2.2-14 2026-01-14 [1] RSPM
future 1.69.0 2026-01-16 [1] RSPM
generics 0.1.4 2025-05-09 [1] RSPM
ggplot2 * 4.0.2 2026-02-03 [1] RSPM
globals 0.19.0 2026-02-02 [1] RSPM
glue 1.8.0 2024-09-30 [1] RSPM
gtable 0.3.6 2024-10-25 [1] RSPM
htmltools 0.5.9 2025-12-04 [1] RSPM
htmlwidgets 1.6.4 2023-12-06 [1] RSPM
jsonlite 2.0.0 2025-03-27 [1] RSPM
kernlab 0.9-33 2024-08-13 [1] RSPM
knitr 1.51 2025-12-20 [1] RSPM
labeling 0.4.3 2023-08-29 [1] RSPM
lattice 0.22-7 2025-04-02 [2] CRAN (R 4.5.2)
lgr 0.5.2 2026-01-30 [1] RSPM
lifecycle 1.0.5 2026-01-08 [1] RSPM
listenv 0.10.0 2025-11-02 [1] RSPM
magrittr 2.0.4 2025-09-12 [1] RSPM
MASS 7.3-65 2025-02-28 [2] CRAN (R 4.5.2)
Matrix 1.7-4 2025-08-28 [2] CRAN (R 4.5.2)
mclust 6.1.2 2025-10-31 [1] RSPM
mlr3 * 1.4.0 2026-02-19 [1] RSPM
mlr3cluster 0.2.0 2026-02-04 [1] RSPM
mlr3cmprsk 0.0.1 2026-02-27 [1] Github (mlr-org/mlr3cmprsk@5a04c29)
mlr3data 0.9.0 2024-11-08 [1] RSPM
mlr3extralearners 1.4.0 2026-01-26 [1] https://m~
mlr3filters 0.9.0 2025-09-12 [1] RSPM
mlr3fselect 1.5.0 2025-11-27 [1] RSPM
mlr3hyperband 1.0.0 2025-07-10 [1] RSPM
mlr3inferr 0.2.1 2025-11-26 [1] RSPM
mlr3learners 0.14.0 2025-12-13 [1] RSPM
mlr3mbo 0.3.3 2025-10-10 [1] RSPM
mlr3measures 1.2.0 2025-11-25 [1] RSPM
mlr3misc 0.21.0 2026-02-26 [1] RSPM
mlr3pipelines 0.10.0 2025-11-07 [1] RSPM
mlr3tuning 1.5.1 2025-12-14 [1] RSPM
mlr3tuningspaces 0.6.0 2025-05-16 [1] RSPM
mlr3verse * 0.3.1 2025-01-14 [1] RSPM
mlr3viz 0.11.0 2026-02-22 [1] RSPM
mlr3website * 0.0.0.9000 2026-02-27 [1] Github (mlr-org/mlr3website@f6e32a7)
modeltools 0.2-24 2025-05-02 [1] RSPM
nnet 7.3-20 2025-01-01 [2] CRAN (R 4.5.2)
otel 0.2.0 2025-08-29 [1] RSPM
palmerpenguins 0.1.1 2022-08-15 [1] RSPM
paradox 1.0.1 2024-07-09 [1] RSPM
parallelly 1.46.1 2026-01-08 [1] RSPM
pillar 1.11.1 2025-09-17 [1] RSPM
pkgconfig 2.0.3 2019-09-22 [1] RSPM
prabclus 2.3-5 2026-01-14 [1] RSPM
R6 2.6.1 2025-02-15 [1] RSPM
RColorBrewer 1.1-3 2022-04-03 [1] RSPM
Rcpp 1.1.1 2026-01-10 [1] RSPM
rlang 1.1.7 2026-01-09 [1] RSPM
rmarkdown 2.30 2025-09-28 [1] RSPM
robustbase 0.99-7 2026-02-05 [1] RSPM
S7 0.2.1 2025-11-14 [1] RSPM
scales 1.4.0 2025-04-24 [1] RSPM
sessioninfo 1.2.3 2025-02-05 [1] RSPM
spacefillr 0.4.0 2025-02-24 [1] RSPM
stringi 1.8.7 2025-03-27 [1] RSPM
survdistr 0.0.1 2026-02-27 [1] Github (mlr-org/survdistr@d7babd1)
survival 3.8-3 2024-12-17 [2] CRAN (R 4.5.2)
tibble 3.3.1 2026-01-11 [1] RSPM
tidyselect 1.2.1 2024-03-11 [1] RSPM
uuid 1.2-2 2026-01-23 [1] RSPM
vctrs 0.7.1 2026-01-23 [1] RSPM
viridisLite 0.4.3 2026-02-04 [1] RSPM
withr 3.0.2 2024-10-28 [1] RSPM
xfun 0.56 2026-01-18 [1] RSPM
yaml 2.3.12 2025-12-10 [1] RSPM
[1] /usr/local/lib/R/site-library
[2] /usr/local/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────References
Bischl, Bernd, Martin Binder, Michel Lang, et al. 2021. “Hyperparameter Optimization: Foundations, Algorithms, Best Practices and Open Challenges.” arXiv:2107.05847 [Cs, Stat], July. http://arxiv.org/abs/2107.05847.