
library("mlr3verse")
learner = lrn("classif.svm", id = "svm", type = "C-classification")Scope
We continue working with the Hyperband optimization algorithm (Li et al. 2018). The previous post used the number of boosting iterations of an XGBoost model as the resource. However, Hyperband is not limited to machine learning algorithms that are trained iteratively. The resource can also be the number of features, the training time of a model, or the size of the training data set. In this post, we will tune a support vector machine and use the size of the training data set as the fidelity parameter. The time to train a support vector machine and the performance increases with the size of the data set. This makes the data set size a suitable fidelity parameter for Hyperband. This is the second part of the Hyperband series. The first part can be found here Hyperband Series - Iterative Training. If you don’t know much about Hyperband, check out the first post which explains the algorithm in detail. We assume that you are already familiar with tuning in the mlr3 ecosystem. If not, you should start with the book chapter on optimization or the Hyperparameter Optimization on the Palmer Penguins Data Set post. A little knowledge about mlr3pipelines is beneficial but not necessary to understand the example.
Hyperparameter Optimization
In this post, we will optimize the hyperparameters of the support vector machine on the Sonar data set. We begin by constructing a classification machine by setting type to "C-classification".
The mlr3pipelines package features a PipeOp for subsampling.
po("subsample")
── PipeOp <subsample>: not trained ─────────────────────────────────────────────────────────────────────────────────────
Values: frac=0.6321, stratify=FALSE, use_groups=TRUE, replace=FALSE
── Input channels:
name train predict
<char> <char> <char>
input Task Task
── Output channels:
name train predict
<char> <char> <char>
output Task TaskThe PipeOp controls the size of the training data set with the frac parameter. We connect the PipeOp with the learner and get a GraphLearner.
graph_learner = as_learner(
po("subsample") %>>%
learner
)The graph learner subsamples and then fits a support vector machine on the data subset. The parameter set of the graph learner is a combination of the parameter sets of the PipeOp and learner.
as.data.table(graph_learner$param_set)[, .(id, lower, upper, levels)] id lower upper levels
<char> <num> <num> <list>
1: subsample.frac 0 Inf [NULL]
2: subsample.stratify NA NA TRUE,FALSE
3: subsample.use_groups NA NA TRUE,FALSE
4: subsample.replace NA NA TRUE,FALSE
5: svm.cachesize -Inf Inf [NULL]
---
16: svm.nu -Inf Inf [NULL]
17: svm.scale NA NA [NULL]
18: svm.shrinking NA NA TRUE,FALSE
19: svm.tolerance 0 Inf [NULL]
20: svm.type NA NA C-classification,nu-classificationNext, we create the search space. We use TuneToken to mark which hyperparameters should be tuned. We have to prefix the hyperparameters with the id of the PipeOps. The subsample.frac is the fidelity parameter that must be tagged with "budget" in the search space. The data set size is increased from 3.7% to 100%. For the other hyperparameters, we took the search space for support vector machines from the Kuehn et al. (2018) article. This search space works for a wide range of data sets.
graph_learner$param_set$set_values(
subsample.frac = to_tune(p_dbl(3^-3, 1, tags = "budget")),
svm.kernel = to_tune(c("linear", "polynomial", "radial")),
svm.cost = to_tune(1e-4, 1e3, logscale = TRUE),
svm.gamma = to_tune(1e-4, 1e3, logscale = TRUE),
svm.tolerance = to_tune(1e-4, 2, logscale = TRUE),
svm.degree = to_tune(2, 5)
)Support vector machines often crash or never finish the training with certain hyperparameter configurations. We set a timeout of 30 seconds and a fallback learner to handle these cases.
graph_learner$encapsulate(method = "evaluate", fallback = lrn("classif.featureless"))
graph_learner$timeout = c(train = 30, predict = 30)Let’s create the tuning instance. We use the "none" terminator because Hyperband controls the termination itself.
instance = ti(
task = tsk("sonar"),
learner = graph_learner,
resampling = rsmp("cv", folds = 3),
measures = msr("classif.ce"),
terminator = trm("none")
)
instance
── <TuningInstanceBatchSingleCrit> ─────────────────────────────────────────────────────────────────────────────────────
• State: Not optimized
• Objective: <ObjectiveTuningBatch>
• Search Space:
id class lower upper nlevels
<char> <char> <num> <num> <num>
1: subsample.frac ParamDbl 0.03703704 1.0000000 Inf
2: svm.cost ParamDbl -9.21034037 6.9077553 Inf
3: svm.degree ParamInt 2.00000000 5.0000000 4
4: svm.gamma ParamDbl -9.21034037 6.9077553 Inf
5: svm.kernel ParamFct NA NA 3
6: svm.tolerance ParamDbl -9.21034037 0.6931472 Inf
• Terminator: <TerminatorNone>We load the Hyperband tuner and set eta = 3.
library("mlr3hyperband")
tuner = tnr("hyperband", eta = 3)Using eta = 3 and a lower bound of 3.7% for the data set size, results in the following schedule. Configurations with the same data set size are evaluated in parallel.
Now we are ready to start the tuning.
tuner$optimize(instance)The best model is a support vector machine with a polynomial kernel.
instance$result[, .(subsample.frac, svm.cost, svm.degree, svm.gamma, svm.kernel, svm.tolerance, classif.ce)] subsample.frac svm.cost svm.degree svm.gamma svm.kernel svm.tolerance classif.ce
<num> <num> <int> <num> <char> <num> <num>
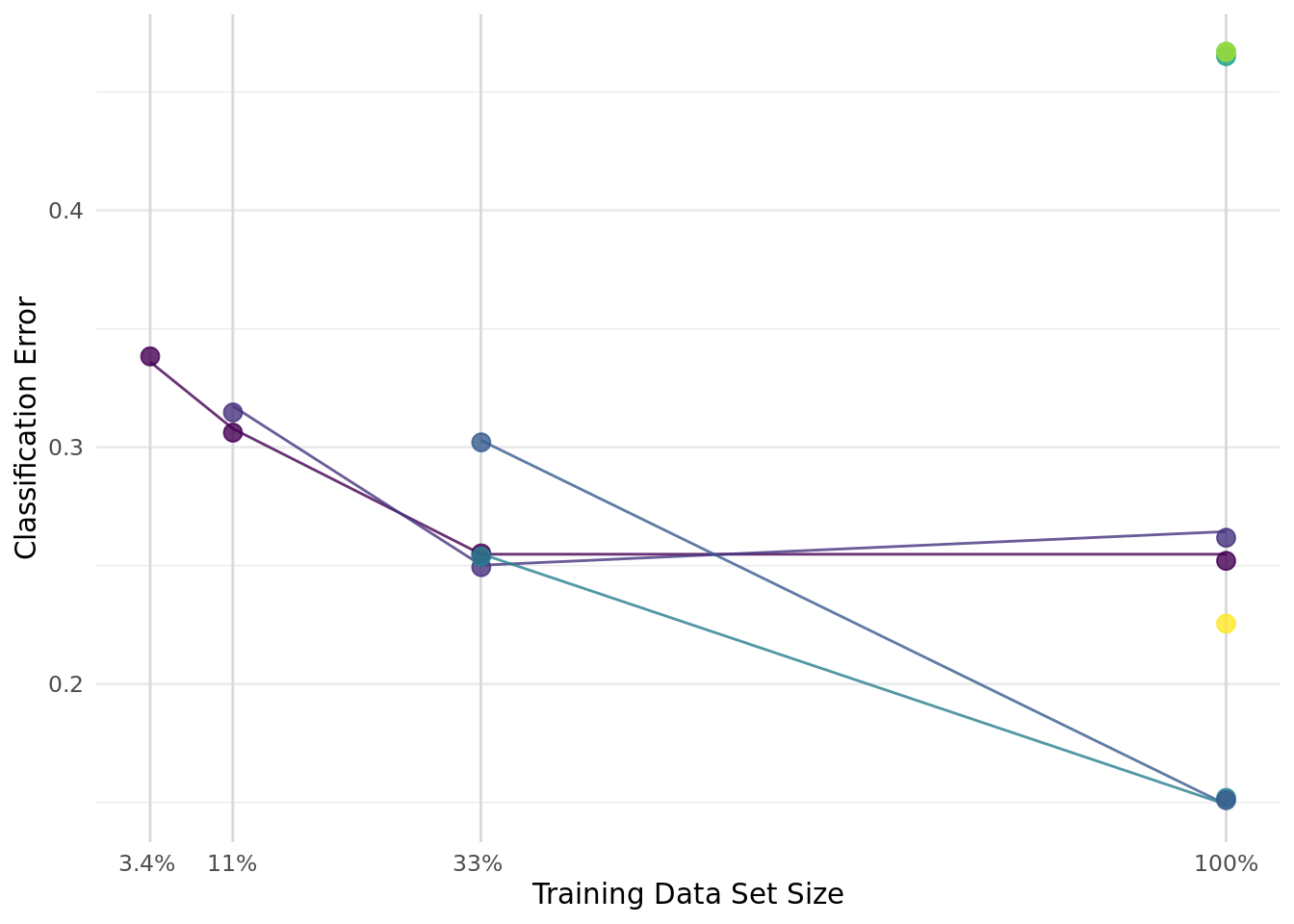
1: 1 -6.149713 3 0.9764394 polynomial -8.985273 0.1873706The archive contains all evaluated configurations. We look at the 8 configurations that were evaluated on the complete data set. The configuration with the best classification error on the full data set was sampled in bracket 2. The classification error was estimated to be 26% on 33% of the data set and increased to 19% on the full data set (see green line in Figure 1).
Conclusion
Using the data set size as the budget parameter in Hyperband allows the tuning of machine learning models that are not trained iteratively. We have tried to keep the runtime of the example low. For your optimization, you should use cross-validation and run multiple iterations of Hyperband.
Session Information
sessioninfo::session_info(info = "packages")═ Session info ═══════════════════════════════════════════════════════════════════════════════════════════════════════
─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
backports 1.5.0 2024-05-23 [1] RSPM
bbotk 1.8.1 2025-11-26 [1] RSPM
checkmate 2.3.4 2026-02-03 [1] RSPM
class 7.3-23 2025-01-01 [2] CRAN (R 4.5.2)
cli 3.6.5 2025-04-23 [1] RSPM
cluster 2.1.8.1 2025-03-12 [2] CRAN (R 4.5.2)
codetools 0.2-20 2024-03-31 [2] CRAN (R 4.5.2)
crayon 1.5.3 2024-06-20 [1] RSPM
crosstalk 1.2.2 2025-08-26 [1] RSPM
data.table * 1.18.2.1 2026-01-27 [1] RSPM
DEoptimR 1.1-4 2025-07-27 [1] RSPM
digest 0.6.39 2025-11-19 [1] RSPM
diptest 0.77-2 2025-08-20 [1] RSPM
dplyr 1.2.0 2026-02-03 [1] RSPM
evaluate 1.0.5 2025-08-27 [1] RSPM
farver 2.1.2 2024-05-13 [1] RSPM
fastmap 1.2.0 2024-05-15 [1] RSPM
flexmix 2.3-20 2025-02-28 [1] RSPM
fpc 2.2-14 2026-01-14 [1] RSPM
future 1.69.0 2026-01-16 [1] RSPM
future.apply 1.20.2 2026-02-20 [1] RSPM
generics 0.1.4 2025-05-09 [1] RSPM
ggplot2 * 4.0.2 2026-02-03 [1] RSPM
globals 0.19.0 2026-02-02 [1] RSPM
glue 1.8.0 2024-09-30 [1] RSPM
gtable 0.3.6 2024-10-25 [1] RSPM
htmltools * 0.5.9 2025-12-04 [1] RSPM
htmlwidgets 1.6.4 2023-12-06 [1] RSPM
jsonlite 2.0.0 2025-03-27 [1] RSPM
kernlab 0.9-33 2024-08-13 [1] RSPM
knitr 1.51 2025-12-20 [1] RSPM
labeling 0.4.3 2023-08-29 [1] RSPM
lattice 0.22-7 2025-04-02 [2] CRAN (R 4.5.2)
lgr 0.5.2 2026-01-30 [1] RSPM
lifecycle 1.0.5 2026-01-08 [1] RSPM
listenv 0.10.0 2025-11-02 [1] RSPM
magrittr 2.0.4 2025-09-12 [1] RSPM
MASS 7.3-65 2025-02-28 [2] CRAN (R 4.5.2)
Matrix 1.7-4 2025-08-28 [2] CRAN (R 4.5.2)
mclust 6.1.2 2025-10-31 [1] RSPM
mlr3 * 1.4.0 2026-02-19 [1] RSPM
mlr3cluster 0.2.0 2026-02-04 [1] RSPM
mlr3cmprsk 0.0.1 2026-02-27 [1] Github (mlr-org/mlr3cmprsk@5a04c29)
mlr3data 0.9.0 2024-11-08 [1] RSPM
mlr3extralearners 1.4.0 2026-01-26 [1] https://m~
mlr3filters 0.9.0 2025-09-12 [1] RSPM
mlr3fselect 1.5.0 2025-11-27 [1] RSPM
mlr3hyperband * 1.0.0 2025-07-10 [1] RSPM
mlr3inferr 0.2.1 2025-11-26 [1] RSPM
mlr3learners 0.14.0 2025-12-13 [1] RSPM
mlr3mbo 0.3.3 2025-10-10 [1] RSPM
mlr3measures 1.2.0 2025-11-25 [1] RSPM
mlr3misc 0.21.0 2026-02-26 [1] RSPM
mlr3pipelines 0.10.0 2025-11-07 [1] RSPM
mlr3tuning * 1.5.1 2025-12-14 [1] RSPM
mlr3tuningspaces 0.6.0 2025-05-16 [1] RSPM
mlr3verse * 0.3.1 2025-01-14 [1] RSPM
mlr3viz 0.11.0 2026-02-22 [1] RSPM
mlr3website * 0.0.0.9000 2026-02-27 [1] Github (mlr-org/mlr3website@f6e32a7)
modeltools 0.2-24 2025-05-02 [1] RSPM
nnet 7.3-20 2025-01-01 [2] CRAN (R 4.5.2)
otel 0.2.0 2025-08-29 [1] RSPM
palmerpenguins 0.1.1 2022-08-15 [1] RSPM
paradox * 1.0.1 2024-07-09 [1] RSPM
parallelly 1.46.1 2026-01-08 [1] RSPM
pillar 1.11.1 2025-09-17 [1] RSPM
pkgconfig 2.0.3 2019-09-22 [1] RSPM
prabclus 2.3-5 2026-01-14 [1] RSPM
R6 2.6.1 2025-02-15 [1] RSPM
RColorBrewer 1.1-3 2022-04-03 [1] RSPM
Rcpp 1.1.1 2026-01-10 [1] RSPM
reactable * 0.4.5 2025-12-01 [1] RSPM
reactR 0.6.1 2024-09-14 [1] RSPM
rlang 1.1.7 2026-01-09 [1] RSPM
rmarkdown 2.30 2025-09-28 [1] RSPM
robustbase 0.99-7 2026-02-05 [1] RSPM
S7 0.2.1 2025-11-14 [1] RSPM
scales 1.4.0 2025-04-24 [1] RSPM
sessioninfo 1.2.3 2025-02-05 [1] RSPM
spacefillr 0.4.0 2025-02-24 [1] RSPM
stringi 1.8.7 2025-03-27 [1] RSPM
survdistr 0.0.1 2026-02-27 [1] Github (mlr-org/survdistr@d7babd1)
survival 3.8-3 2024-12-17 [2] CRAN (R 4.5.2)
tibble 3.3.1 2026-01-11 [1] RSPM
tidyselect 1.2.1 2024-03-11 [1] RSPM
uuid 1.2-2 2026-01-23 [1] RSPM
vctrs 0.7.1 2026-01-23 [1] RSPM
viridisLite 0.4.3 2026-02-04 [1] RSPM
withr 3.0.2 2024-10-28 [1] RSPM
xfun 0.56 2026-01-18 [1] RSPM
yaml 2.3.12 2025-12-10 [1] RSPM
[1] /usr/local/lib/R/site-library
[2] /usr/local/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────References
Kuehn, Daniel, Philipp Probst, Janek Thomas, and Bernd Bischl. 2018. Automatic Exploration of Machine Learning Experiments on OpenML. https://arxiv.org/abs/1806.10961.
Li, Lisha, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. 2018. “Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization.” Journal of Machine Learning Research 18 (185): 1–52. https://jmlr.org/papers/v18/16-558.html.