
library(mlr3verse)Scope
Feature selection is the process of finding an optimal set of features to improve the performance, interpretability and robustness of machine learning algorithms. In this article, we introduce the Shadow Variable Search algorithm which is a wrapper method for feature selection. Wrapper methods iteratively add features to the model that optimize a performance measure. As an example, we will search for the optimal set of features for a support vector machine on the Pima Indian Diabetes data set. We assume that you are already familiar with the basic building blocks of the mlr3 ecosystem. If you are new to feature selection, we recommend reading the feature selection chapter of the mlr3book first. Some knowledge about mlr3pipelines is beneficial but not necessary to understand the example.
Shadow Variable Search
Adding shadow variables to a data set is a well-known method in machine learning (Wu et al. 2007; Thomas et al. 2017). The idea is to add permutated copies of the original features to the data set. These permutated copies are called shadow variables or pseudovariables and the permutation breaks any relationship with the target variable, making them useless for prediction. The subsequent search is similar to the sequential forward selection algorithm, where one new feature is added in each iteration of the algorithm. This new feature is selected as the one that improves the performance of the model the most. This selection is computationally expensive, as one model for each of the not yet included features has to be trained. The difference between shadow variable search and sequential forward selection is that the former uses the selection of a shadow variable as the termination criterion. Selecting a shadow variable means that the best improvement is achieved by adding a feature that is unrelated to the target variable. Consequently, the variables not yet selected are most likely also correlated to the target variable only by chance. Therefore, only the previously selected features have a true influence on the target variable.
mlr3fselect is the feature selection package of the mlr3 ecosystem. It implements the shadow variable search algorithm. We load all packages of the ecosystem with the mlr3verse package.
We retrieve the shadow variable search optimizer with the fs() function. The algorithm has no control parameters.
optimizer = fs("shadow_variable_search")Task and Learner
The objective of the Pima Indian Diabetes data set is to predict whether a person has diabetes or not. The data set includes 768 patients with 8 measurements (see Figure 1).
task = tsk("pima")Code
library(ggplot2)
library(data.table)
data = melt(as.data.table(task), id.vars = task$target_names, measure.vars = task$feature_names)
ggplot(data, aes(x = value, fill = diabetes)) +
geom_density(alpha = 0.5) +
facet_wrap(~ variable, ncol = 8, scales = "free") +
scale_fill_viridis_d(end = 0.8) +
theme_minimal() +
theme(axis.title.x = element_blank())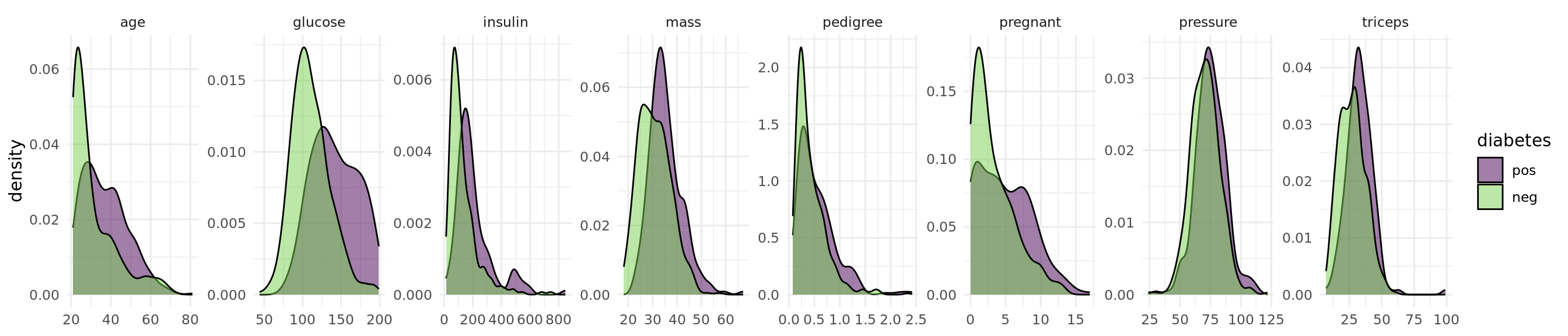
The data set contains missing values.
task$missings()diabetes age glucose insulin mass pedigree pregnant pressure triceps
0 0 5 374 11 0 0 35 227 Support vector machines cannot handle missing values. We impute the missing values with the histogram imputation method.
learner = po("imputehist") %>>% lrn("classif.svm", predict_type = "prob")Feature Selection
Now we define the feature selection problem by using the fsi() function that constructs an FSelectInstanceBatchSingleCrit. In addition to the task and learner, we have to select a resampling strategy and performance measure to determine how the performance of a feature subset is evaluated. We pass the "none" terminator because the shadow variable search algorithm terminates by itself.
instance = fsi(
task = task,
learner = learner,
resampling = rsmp("cv", folds = 3),
measures = msr("classif.auc"),
terminator = trm("none")
)We are now ready to start the shadow variable search. To do this, we simply pass the instance to the $optimize() method of the optimizer.
optimizer$optimize(instance) age glucose insulin mass pedigree pregnant pressure triceps features n_features classif.auc
<lgcl> <lgcl> <lgcl> <lgcl> <lgcl> <lgcl> <lgcl> <lgcl> <list> <int> <num>
1: TRUE TRUE FALSE TRUE TRUE FALSE FALSE FALSE age,glucose,mass,pedigree 4 0.835165The optimizer returns the best feature set and the corresponding estimated performance.
Figure 2 shows the optimization path of the feature selection. The feature glucose was selected first and in the following iterations age, mass and pedigree. Then a shadow variable was selected and the feature selection was terminated.
Code
library(data.table)
library(ggplot2)
library(mlr3misc)
library(viridisLite)
data = as.data.table(instance$archive)[order(-classif.auc), head(.SD, 1), by = batch_nr][order(batch_nr)]
data[, features := map_chr(features, str_collapse)]
data[, batch_nr := as.character(batch_nr)]
ggplot(data, aes(x = batch_nr, y = classif.auc)) +
geom_bar(
stat = "identity",
width = 0.5,
fill = viridis(1, begin = 0.5),
alpha = 0.8) +
geom_text(
data = data,
mapping = aes(x = batch_nr, y = 0, label = features),
hjust = 0,
nudge_y = 0.05,
color = "white",
size = 5
) +
coord_flip() +
xlab("Iteration") +
theme_minimal()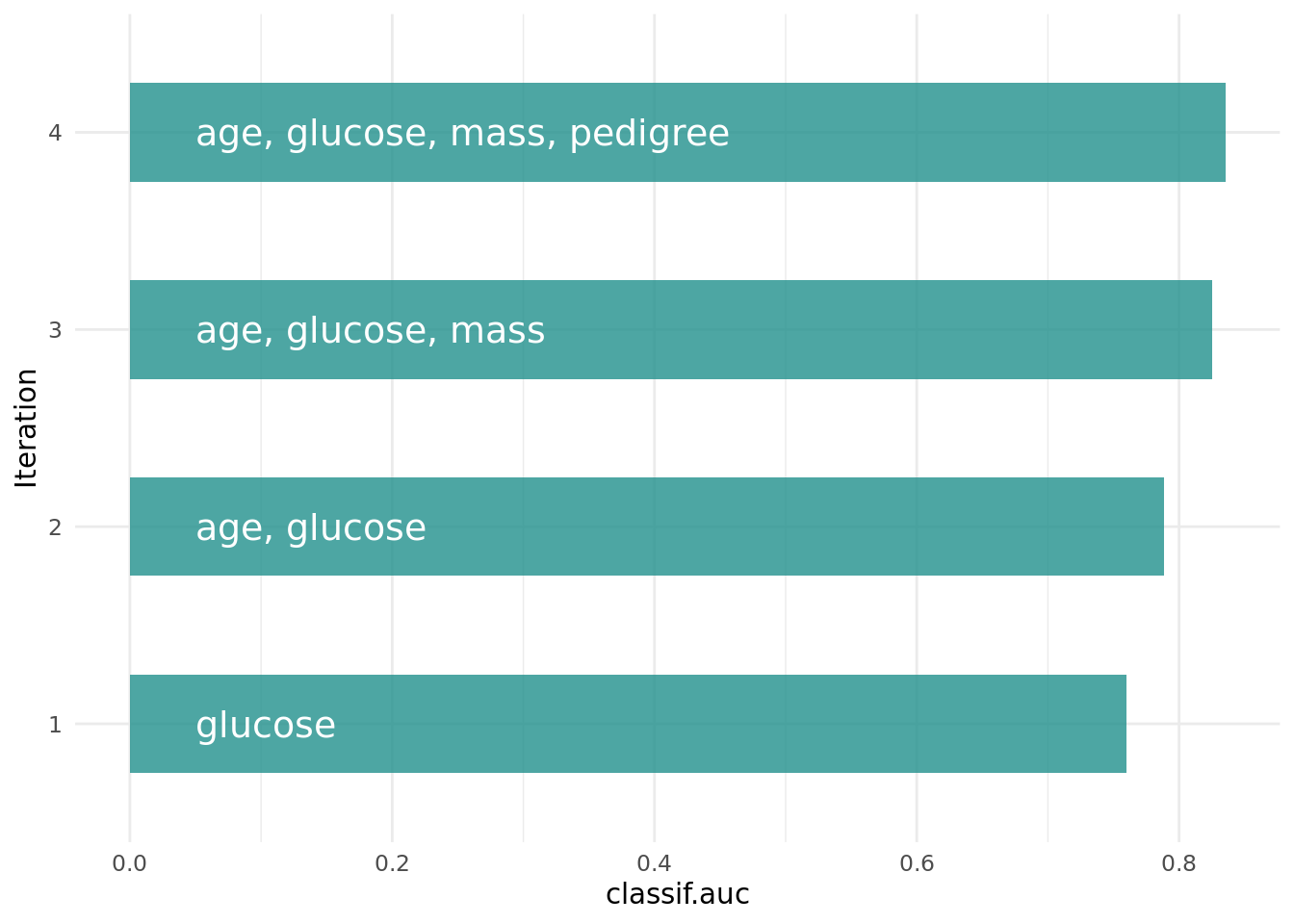
The archive contains all evaluated feature sets. We can see that each feature has a corresponding shadow variable. We only show the variables age, glucose and insulin and their shadow variables here.
as.data.table(instance$archive)[, .(age, glucose, insulin, permuted__age, permuted__glucose, permuted__insulin, classif.auc)] age glucose insulin permuted__age permuted__glucose permuted__insulin classif.auc
<lgcl> <lgcl> <lgcl> <lgcl> <lgcl> <lgcl> <num>
1: TRUE FALSE FALSE FALSE FALSE FALSE 0.6437052
2: FALSE TRUE FALSE FALSE FALSE FALSE 0.7598155
3: FALSE FALSE TRUE FALSE FALSE FALSE 0.4900280
4: FALSE FALSE FALSE FALSE FALSE FALSE 0.6424026
5: FALSE FALSE FALSE FALSE FALSE FALSE 0.5690107
---
54: TRUE TRUE FALSE FALSE FALSE FALSE 0.8266713
55: TRUE TRUE FALSE FALSE FALSE FALSE 0.8063568
56: TRUE TRUE FALSE FALSE FALSE FALSE 0.8244232
57: TRUE TRUE FALSE FALSE FALSE FALSE 0.8234605
58: TRUE TRUE FALSE FALSE FALSE FALSE 0.8164784Final Model
The learner we use to make predictions on new data is called the final model. The final model is trained with the optimal feature set on the full data set. We subset the task to the optimal feature set and train the learner.
task$select(instance$result_feature_set)
learner$train(task)The trained model can now be used to predict new, external data.
Conclusion
The shadow variable search is a fast feature selection method that is easy to use. More information on the theoretical background can be found in Wu et al. (2007) and Thomas et al. (2017). If you want to know more about feature selection in general, we recommend having a look at our book.
Session Information
sessioninfo::session_info(info = "packages")═ Session info ═══════════════════════════════════════════════════════════════════════════════════════════════════════
─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
backports 1.5.0 2024-05-23 [1] RSPM
bbotk 1.8.1 2025-11-26 [1] RSPM
checkmate 2.3.4 2026-02-03 [1] RSPM
class 7.3-23 2025-01-01 [2] CRAN (R 4.5.2)
cli 3.6.5 2025-04-23 [1] RSPM
cluster 2.1.8.1 2025-03-12 [2] CRAN (R 4.5.2)
codetools 0.2-20 2024-03-31 [2] CRAN (R 4.5.2)
crayon 1.5.3 2024-06-20 [1] RSPM
data.table * 1.18.2.1 2026-01-27 [1] RSPM
DEoptimR 1.1-4 2025-07-27 [1] RSPM
digest 0.6.39 2025-11-19 [1] RSPM
diptest 0.77-2 2025-08-20 [1] RSPM
dplyr 1.2.0 2026-02-03 [1] RSPM
e1071 1.7-17 2025-12-18 [1] RSPM
evaluate 1.0.5 2025-08-27 [1] RSPM
farver 2.1.2 2024-05-13 [1] RSPM
fastmap 1.2.0 2024-05-15 [1] RSPM
flexmix 2.3-20 2025-02-28 [1] RSPM
fpc 2.2-14 2026-01-14 [1] RSPM
future 1.69.0 2026-01-16 [1] RSPM
future.apply 1.20.2 2026-02-20 [1] RSPM
generics 0.1.4 2025-05-09 [1] RSPM
ggplot2 * 4.0.2 2026-02-03 [1] RSPM
globals 0.19.0 2026-02-02 [1] RSPM
glue 1.8.0 2024-09-30 [1] RSPM
gtable 0.3.6 2024-10-25 [1] RSPM
htmltools 0.5.9 2025-12-04 [1] RSPM
htmlwidgets 1.6.4 2023-12-06 [1] RSPM
jsonlite 2.0.0 2025-03-27 [1] RSPM
kernlab 0.9-33 2024-08-13 [1] RSPM
knitr 1.51 2025-12-20 [1] RSPM
labeling 0.4.3 2023-08-29 [1] RSPM
lattice 0.22-7 2025-04-02 [2] CRAN (R 4.5.2)
lgr 0.5.2 2026-01-30 [1] RSPM
lifecycle 1.0.5 2026-01-08 [1] RSPM
listenv 0.10.0 2025-11-02 [1] RSPM
magrittr 2.0.4 2025-09-12 [1] RSPM
MASS 7.3-65 2025-02-28 [2] CRAN (R 4.5.2)
Matrix 1.7-4 2025-08-28 [2] CRAN (R 4.5.2)
mclust 6.1.2 2025-10-31 [1] RSPM
mlr3 * 1.4.0 2026-02-19 [1] RSPM
mlr3cluster 0.2.0 2026-02-04 [1] RSPM
mlr3cmprsk 0.0.1 2026-02-27 [1] Github (mlr-org/mlr3cmprsk@5a04c29)
mlr3data 0.9.0 2024-11-08 [1] RSPM
mlr3extralearners 1.4.0 2026-01-26 [1] https://m~
mlr3filters 0.9.0 2025-09-12 [1] RSPM
mlr3fselect 1.5.0 2025-11-27 [1] RSPM
mlr3hyperband 1.0.0 2025-07-10 [1] RSPM
mlr3inferr 0.2.1 2025-11-26 [1] RSPM
mlr3learners 0.14.0 2025-12-13 [1] RSPM
mlr3mbo 0.3.3 2025-10-10 [1] RSPM
mlr3measures 1.2.0 2025-11-25 [1] RSPM
mlr3misc * 0.21.0 2026-02-26 [1] RSPM
mlr3pipelines 0.10.0 2025-11-07 [1] RSPM
mlr3tuning 1.5.1 2025-12-14 [1] RSPM
mlr3tuningspaces 0.6.0 2025-05-16 [1] RSPM
mlr3verse * 0.3.1 2025-01-14 [1] RSPM
mlr3viz 0.11.0 2026-02-22 [1] RSPM
mlr3website * 0.0.0.9000 2026-02-27 [1] Github (mlr-org/mlr3website@f6e32a7)
modeltools 0.2-24 2025-05-02 [1] RSPM
nnet 7.3-20 2025-01-01 [2] CRAN (R 4.5.2)
otel 0.2.0 2025-08-29 [1] RSPM
palmerpenguins 0.1.1 2022-08-15 [1] RSPM
paradox 1.0.1 2024-07-09 [1] RSPM
parallelly 1.46.1 2026-01-08 [1] RSPM
pillar 1.11.1 2025-09-17 [1] RSPM
pkgconfig 2.0.3 2019-09-22 [1] RSPM
prabclus 2.3-5 2026-01-14 [1] RSPM
proxy 0.4-29 2025-12-29 [1] RSPM
R6 2.6.1 2025-02-15 [1] RSPM
RColorBrewer 1.1-3 2022-04-03 [1] RSPM
Rcpp 1.1.1 2026-01-10 [1] RSPM
rlang 1.1.7 2026-01-09 [1] RSPM
rmarkdown 2.30 2025-09-28 [1] RSPM
robustbase 0.99-7 2026-02-05 [1] RSPM
S7 0.2.1 2025-11-14 [1] RSPM
scales 1.4.0 2025-04-24 [1] RSPM
sessioninfo 1.2.3 2025-02-05 [1] RSPM
spacefillr 0.4.0 2025-02-24 [1] RSPM
stringi 1.8.7 2025-03-27 [1] RSPM
survdistr 0.0.1 2026-02-27 [1] Github (mlr-org/survdistr@d7babd1)
survival 3.8-3 2024-12-17 [2] CRAN (R 4.5.2)
tibble 3.3.1 2026-01-11 [1] RSPM
tidyselect 1.2.1 2024-03-11 [1] RSPM
uuid 1.2-2 2026-01-23 [1] RSPM
vctrs 0.7.1 2026-01-23 [1] RSPM
viridisLite * 0.4.3 2026-02-04 [1] RSPM
withr 3.0.2 2024-10-28 [1] RSPM
xfun 0.56 2026-01-18 [1] RSPM
yaml 2.3.12 2025-12-10 [1] RSPM
[1] /usr/local/lib/R/site-library
[2] /usr/local/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────References
Thomas, Janek, Tobias Hepp, Andreas Mayr, and Bernd Bischl. 2017. “Probing for Sparse and Fast Variable Selection with Model-Based Boosting.” Computational and Mathematical Methods in Medicine 2017 (July): e1421409. https://doi.org/10.1155/2017/1421409.
Wu, Yujun, Dennis D Boos, and Leonard A Stefanski. 2007. “Controlling Variable Selection by the Addition of Pseudovariables.” Journal of the American Statistical Association 102 (477): 235–43. https://doi.org/10.1198/016214506000000843.